|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Click here to view the complete list of archived articles
This article was originally published in the Fall 2005 issue of Methods & Tools
Domain-Specific Modeling for Full Code Generation
Juha-Pekka Tolvanen, MetaCase, www.metacase.com
Domain-Specific Modeling raises the level of abstraction beyond programming by specifying the solution directly using domain concepts. The final products are generated from these high-level specifications. This automation is possible because both the language and generators need fit the requirements of only one company and domain. This article describes Domain-Specific Modeling (DSM) with examples and compares it to UML and MDA.
UML for code generation?
Generating complete code from models has been an industry goal for many years. Models serve as mechanisms for better understanding and documentation, but they can also be used for generating complete and working code. This automates development leading to improved productivity, quality and complexity hiding.
Unfortunately, many current modeling languages are based on the code world and offer only modest possibilities to raise design abstraction and to achieve full code generation. For example, UML uses directly programming concepts (classes, return values, etc.) as modeling constructs. Having a rectangle symbol to illustrate a class in a diagram and then equivalent textual presentation in a programming language does not provide real generation possibilities – the level of abstraction in models and code is the same! As a consequence of this, developers easily find themselves making models that describe functionality and behavior that they find easier to write directly as code. The limited code generation possibilities force developers to start manual programming after design. It has also lead to round-trip problems: Having the same information in two places, code and models, is a recipe for trouble.
Domain-Specific modeling solution
Generation challenges can be solved in a similar manner as in the past with programming languages: by continuing to raise abstraction. Models should not be conceived to visualize code, but describe higher-level abstractions above programming languages. Similarly, in the past it was better to move to C to raise the abstraction than start visualizing Assembler code!
In Domain-Specific Modeling (DSM), the model elements represent things in the domain world, not the code world. The modeling language follows the domain abstractions and semantics, allowing modelers to perceive themselves as working directly with domain concepts. The rules of the domain can be included into the language as constraints, ideally making it impossible to specify illegal or unwanted design models. The close alignment of language and problem domain offers several benefits. Many of these are common to other ways of moving towards higher levels of abstraction: improved productivity, better hiding of complexity, and better system quality.
The higher level of abstraction varies between applications and products, though. Every domain contains its own specific concepts and correctness constraints. Therefore, modeling languages need to be specific for each domain. Let’s take an example. If we are developing a portal for insurance product comparison and purchase, why not use the insurance terminology directly in the design language? Language concepts like ‘Risk’, ‘Bonus’ and ‘Damage’ capture facts about insurances better than Java classes do. An insurance-specific language can also guarantee that the products modeled are valid: insurance without a premium is not a good product, so such a product should be impossible to design. These domain concepts are typically already known and in use, are more natural and reflect already the underlying computational models needed to design the products. Final code (assembler, 3GL, object-oriented etc.) can be still generated from these high-level specifications. Cornerstone for the automated code generation from models is that both the language and generators need fit only company’s requirements.
DSM examples
Let’s demonstrate DSM next using practical examples. We show here three cases from different application domains: cellular phone application, business process workflow and voice menus in an 8-bit microcontroller. These samples focus on application logic and behavior, not just the static structures that are usually easier to generate.
Symbian Series 60 phone applications
Suppose you develop enterprise applications for cellular phones. Your developers make then applications such as inventory status checking, ordering, event registration etc. Before any new applications can be built developers must design them in the phone domain. This involves applying the terms and rules of the phone, such as lists, softkey buttons, views, text messages and user’s actions. DSM would apply these very same concepts directly in the modeling language.
An example of such a modeling language is illustrated in Figure 1a. If you are familiar with some phone applications, like phone book or calendar, you most likely already understood what the above application makes. A user can register for a conference using text messages, choose a payment method, view program and speaker data, browse the conference program via the web, or cancel his registration.
The design model is directly based on domain concepts, such as Note, Pop-up, Text Message, Form, and Query. DSM uses these widgets and services of the phone as modeling concepts and ensures that the phone’s programming model is followed. It also prevents many illegal or unwanted designs – e.g. those leading to poor performance. The specific generator produces then full code from the design model calling the phone’s platform services and executes the result in an emulator or in the target device (Figure1b).
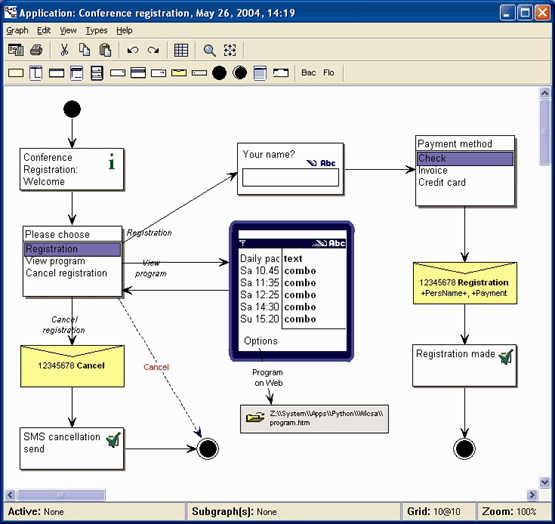
Figure 1a. DSM for designing phone applications
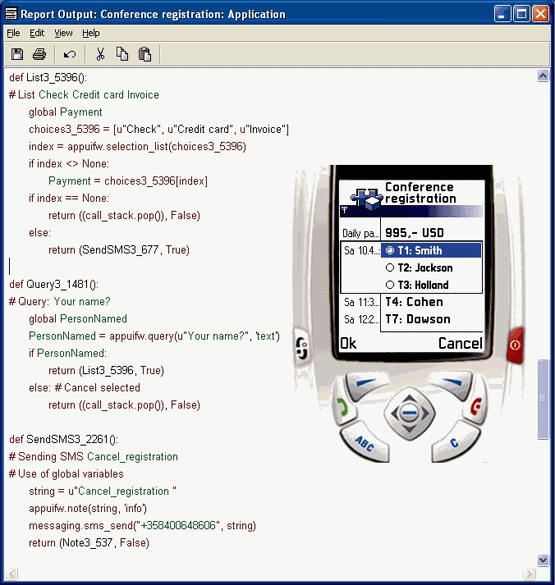
Fig1b. Generating and executing code on target
Here DSM allows scaling up to significant levels of complexity without losing agility. Even in case fundamental changes in the architecture or platform services occur it is typically adequate to just change the generator or the modeling language.
Business process modeling for workflow execution
This example illustrates how software can be generated based on business process models. Business managers can focus on finding the solution for the company’s business processes using natural and well-known concepts. They draw models using concepts like Processes of different kind, Events, Sub-processes, Organizational units etc. as illustrated in Figure 2a. DSM provides these basic modeling concepts along the rules how processes can be defined.
This DSM is also made for generation purposes to produce workflow descriptions in a format that a workflow engine can execute. Making the generator also becomes easier as the specifications don’t need to be verified – the DSM language and related constraints have already taken care of that.
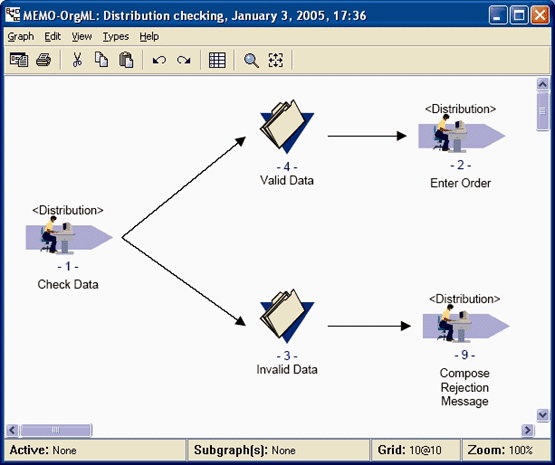
Figure 2a. DSM for business processes
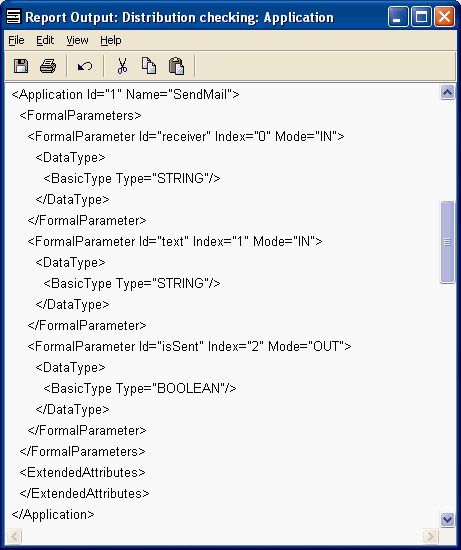
Figure 2b. Generated workflow in XML
Voice menus for an 8-bit microcontroller
This example illustrates a DSM for developing voice menus for a home automation system. Because the target device has limited memory and other resources the DSM aims at optimizing the code. Figure 3a illustrates the flow-like execution of a voice menu system.
The DSM provides predefined abstractions that fit to this particular development need. For developers it is far more natural to think about voice communication logic as ‘Menu’, ‘Prompt’, and ‘Voice entry’ than with Assembler mnemonics.
The generator produces assembler with the necessary functionality for memory addressing, calculation, etc. (Figure 3b). It is worthwhile to note that even though the target platform and source code are on a very low level, the DSM language can still operate on pure domain concepts like menu item, voice message and menu selection. Hence, by changing the generator we could produce for instance C from the same designs.
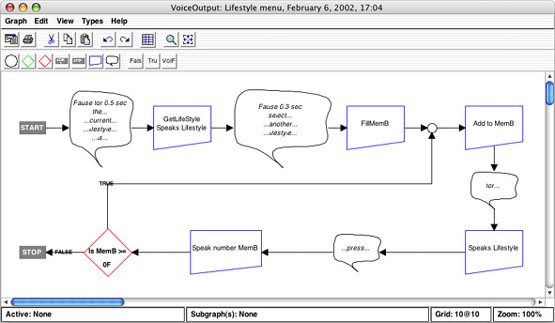
Figure 3a. DSM for voice menu design
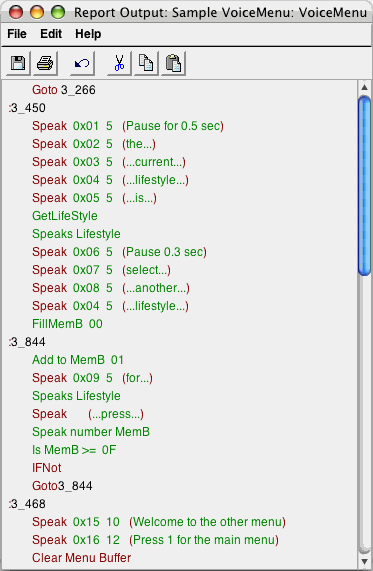
Figure 3b. Generated 8-bit code to microcontroller
DSM benefits to developers
The above examples illustrate what DSM looks like and can offer for developers. A higher level of abstraction generally leads to better productivity. This means not only the time and resources to make the designs in the first place, but the also the maintenance resources.
Requirements changes usually come via the problem domain not the implementation domain, so making such changes in a modeling language that uses domain terms is easier. In addition, in some domains, non-programmers can make complete specifications – and run generators to produce the code.
Keeping specifications at a significantly higher level of abstraction than traditional source code or e.g. class diagrams means less specification work. As the language need fit only a specific domain, usually inside only one company, the DSM can be very lightweight. It does not include techniques or constructs that add unnecessary work for developers.
DSM reduces the need of learning new semantics. Problem domain concepts are typically already known and used, well-defined semantics exist and are considered "natural" as they are formed internally. Because domain-specific semantics must be mastered anyway, why not give them first class status? Developers do not need to learn additional semantics (e.g. UML) and map back and forth between domain and UML semantics. This unnecessary mapping takes time and resources, is error-prone, and is carried out by all designers – some doing it better, but often all differently.
DSM leads to a better quality system, mainly because of two reasons. First, DSM can include correctness rules of the domain making it difficult, and often impossible, to draw illegal or unwanted specifications. This is also a far cheaper way to eliminate bugs: the earlier the better. Second, generators provide mapping to a lower abstraction level, normally code, and the generated result does not need to be edited afterwards. This has been the cornerstone of other successful shifts made with programming languages.
Finally, specifications made with domain terms are normally easier to read, understand, remember, validate and communicate with.
How to implement DSM
To get the DSM benefits of improved productivity, quality and complexity hiding, we need a domain-specific language and generators. In the past, you would also have needed to implement the supporting tool set. This was one of the main reasons holding DSM back: after all, implementing CASE tools is hardly a core competence for most organizations.
Today, the work needed is reduced to just defining the language and generators, since open metamodel-based tools for modeling and code generation are available. These tools allow getting a working DSM environment ready within days instead of months, as in case with tools that require additional manual programming. Even more crucial is keeping the development environment responsive to domain changes: these tools can maintain models in synch with language and generator evolution thus making design work safe in real-world industry settings.
We will use the previous Symbian phone application modeling language (Figure 1a) as an example to explain DSM implementation.
Defining the modeling language for a domain
Defining a modeling language involves three aspects: the domain concepts, the notation used to represent these in graphical models, and the rules that guide the modeling process. Defining a complete language is considered a difficult task: this is certainly true if you want to build a language for everyone. The task eases considerably if you make it only for one problem domain in one company.
The key issue for finding domain concepts is the expertise provided by a domain expert or a small team of them. Typically, the expert is an experienced developer who has already developed several products in this domain. He may have developed the architecture behind the products, or been responsible for forming the component library. He can easily identify the domain concepts from its terminology, existing system descriptions, and component services.
In our phone application example, the domain concepts come from the UI elements (e.g. Form, Popup), menu and button structure (user definable keys, menu) and underlying services (e.g. text messages, web browsing). By allocating these concepts to the modeling language and refining them further, we can create the conceptual part of the modeling language. The goal here is to make the chosen concepts map accurately to the domain semantics.
However, pure domain concepts alone do not make a modeling language: we need the domain knowledge of how they can be put together. For this domain, we choose application flow as the basic model of computation. This describes how the domain concepts interact during the application execution (see Figure 1a for an example). We introduce the concepts of Start and Stop and directed flows – with and without conditions. Conditions are used when the user selects one of several possible choices, for example via a list or a menu. We also add concepts for Library code, making it possible to link in third party extensions and call them with parameters.
Next, these basic concepts are enriched with the domain rules. Typically, the rules constrain the use of the language by defining what kinds of connections between concepts are possible. They can specify how certain concepts can be reused and how models can be organized. In our phone example, rules define which UI elements may have their own menus, which have user-defined buttons, and how different phone services may be called during the application execution. These rules together with the concepts are codified and formalized into a language specification which is often called as a metamodel. A metamodel describes the modeling language, similarly to the way a model describes an application.
To provide the notation part of the modeling language, we define symbols to be the graphical representations of the modeling concepts. As our example domain is user interface related, we can base many of its symbols on the appearance of the phone widgets themselves.
Defining the domain framework
The domain framework provides the interface between the generated code and the underlying platform. In some cases, no extra framework code is needed: generated code can directly call the platform components and their services are enough. Often, though, it is good to define some extra framework utility code or components to make code generation easier. Such components may already exist from earlier development efforts and products, and just need a little tweaking.
In our example, the Symbian/Series 60 enterprise application framework already offers a good set of services, at a higher level than base Series 60. The domain framework thus adds only two functions: a dispatcher to execute the flow of application logic, and view management for multi-view applications.
Developing the code generator
Finally, we want to close the gap between the model and code world by defining the code generator. The generator specifies how information is extracted from the models and transformed into code. The code will be linked with the framework and compile to a finished executable without any additional manual effort. The generated code is thus simply an intermediate by-product on the way to the finished product, like .o files in C compilation.
The key issue in building a code generator is how the models concepts are mapped to code. The domain framework and component library can make this task easier by raising the level of abstraction on the code side. In the simplest cases, each modeling symbol produces certain fixed code, including the values entered into the symbol as arguments. The generator can also generate different code depending on the values in the symbol, the relationships it has with other symbols, or other information in the model.
A simple example of a generator definition for a Note dialog is presented in Figure 4. The Note opens a dialog with information, like "Conference Registration: Welcome" in Figure 1a. Lines 1 and 6 are simply the structure for a generator. Line 2 creates the function definition signature and line 3 a comment. Function naming is based on an internal name that the generator can produce if the developer does not want to give each symbol its own function name.
1 report '_Note'
2 'def '; subreport; '_Internal name'; run; '():'; newline;
3 '# Note '; :Text; newline;
4 ' appuifw.note(u"'; :Text; '", '''; :Note type; ''')'; newline;
5 subreport; '_next element'; run;
6 endreport
Figure 4. Code generator for Note dialog
Line 4 produces the call for the platform service. It uses the model data (underlined here for clarity), like the value for the Text property of the Note UI element (in this case, "Conference Registration: Welcome"). Similarly, the modeler chose the ‘Note type’ value in the model from a list of available notification types, like ‘info’ (here) or ‘confirmation’ (used in "Registration made" in Figure 1). The generated line 4 is thus (with model data underlined):
appuifw.note(u"Conference Registration: Welcome ", 'info')
Since the code generator automates the mapping from model to implementation, every developer makes the Note dialog call similarly: the way the experienced developer has defined it. Finally, line 5 calls another generator definition to follow the application flow to the next phone service or UI element. This generator, named _next element, is also used by other UI elements similar to Notifications.
The generation is not limited to just calling services available from components. The components can also call back to generated code, or generated code can inherit abstract functionality from available code and implement the concrete functionality using design data. The generator can also produce code that the application framework requires but is tedious to design. This minimizes the modeling work and can also hide complexity. In our phone case, for instance, pressing the Cancel button in a dialog need not normally be modeled, as the generator can produce default code that backtracks to the previous element.
As the examples illustrate, DSM only works because it dedicates both the modeling language and code generator to one single domain. Thus model-based code generation can be complete and the generated code efficient. Even if you find code not to be efficient, you most likely can also correct it directly via the generator.
How DSM differs from MDA?
Having demonstrated with examples the main principles of Domain-Specific Modeling we can now compare it to other main model-based development approaches and especially to OMG’s Model-Driven Architecture (MDA). At its most basic, MDA involves transforming UML models on a higher level of abstraction into UML models on a lower level of abstraction. Normally there are two levels, platform-independent models (PIMs) and platform-specific models (PSMs). These PIMs and PSMs are plain UML and thus offer no raise in abstraction.
In MDA, at each stage you edit the models in more detail, reverse and round-trip engineer this and in the end you generate substantial code from the final model. The aim the OMG has with MDA is to achieve the ability to use the same PIM on different software platforms and to standardize all translations and model formats so that models become portable between tools from different vendors. Achieving this is very ambitious but also still many years away. This focus however clearly defines the difference between DSM and MDA, and answers the question of when each should be applied.
DSM requires domain expertise, a capability a company can achieve only when continuously working in the same problem domain. These are typically product or system development houses more than project houses. Here platform independence is not an urgent need, although it can be easily achieved with DSM by having different code generators for different software and/or product platforms. Instead, the main focus of DSM is to significantly improve developer productivity.
With MDA, the OMG does not focus on using DSM languages but on generic UML, their own standard modeling language. It is not looking to encapsulate the domain expertise that may exist in a company but assumes this expertise is not present or not relevant. It seems therefore that MDA, if and when the OMG finally achieves the goals it has set for it, would be suitable for systems or application integration projects.
MDA requires a profound knowledge of its methodology, something which is external to the company and has to be gained by experience. Thus whereas the domain expertise needed for DSM is already available and applied in an organization, MDA expertise has to be gained or purchased from outside. In these situations the choice between MDA and DSM is often clear.
Using DSM
Domain-Specific Modeling allows faster development, based on models of the problem domain rather than on models of the code. Our three examples give some illustrations of this. Industrial experiences of DSM show major improvements in productivity, lower development costs and better quality. For example, Nokia states that in this way it now develops mobile phones up to 10 times faster, and Lucent that it improves their productivity by 3-10 times depending on the product. The key factors contributing to this are:
- The problem is solved only once at a high level of abstraction and the final code is generated straight from this solution.
- The focus of developers shifts from the code to the design, the problem itself. Complexity and implementation details can be hidden, and already familiar terminology is emphasized.
- Consistency of products and lower error-rates are achieved thanks to the better uniformity of the development environment and reduced switching between the levels of design and implementation.
- The domain knowledge is made explicit for the development team, being captured in the modeling language and its tool support.
Implementation of DSM is not an extra investment if you consider the whole cycle from design to working code. Rather,it saves development resources: Traditionally all developers work with the problem domain concepts and map them to the implementation concepts manually. And among developers, there are big differences. Some do it better, but many not so well. So let the experienced developers define the concepts and mapping once, and others need not do it again. If an expert specifies the code generator, it produces applications with better quality than could be achieved by normal developers by hand.
Resources
- Pohjonen, R., Kelly, S., Domain-Specific Modeling, Dr. Dobb's Journal, August (2002)
- Greenfield et al. Software Factories: Assembling Applications with Patterns, Models, Frameworks, and Tools, Wiley (2004)
- Fowler, M., Language Workbenches: The Killer-App for Domain Specific Languages? (http://martinfowler.com/articles/languageWorkbench.html)
- Tolvanen, J.-P, Making model-based code generation work, Embedded Systems, 2004 (http://i.cmpnet.com/embedded/europe/esesep04/esesep04p36.pdf)
- DSMforum.org (www.DSMForum.org)
- Metamodel.com (www.metamodel.com)
- Object Management Group (www.omg.org)
|
Methods & Tools Testmatick.com Software Testing Magazine The Scrum Expert |
|
Browse a selected list of upcoming Software Development Conferences |
Copyright © by 1995-2024 Martinig & Associates |
Privacy
Follow Methods & Tools on


