|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Approval Testing: Agile Testing that Scales
Geoff Bache, Jeremias Rößler
Did you ever change your software in such a way that it broke the majority of your tests and led to major test maintenance work?
Tests are a form of the specification of the software. That is why, in an agile world where software never "stabilizes", tests can quickly move from being a pillar of quality to a burden and hindrance to change. Approval Testing mitigates this risk by removing the need for explicit assertions and instead managing changes to the system behaviour. Read this article to find out how it can help you 1) create automated tests more quickly ;2) have them test more thoroughly and 3) have them adapt much more easily than you ever thought was possible, also when a large amount of functionality is under test.
Disinherited
I stand now before the Old Test Suite. An artefact of a bygone age, yet only a few years old. My team's history in 10,000 lines of test code, lovingly created and beautifully crafted at great expense. And yet I cannot read these books my predecessors wrote. The tests have not worked for some time now, abandoned in the face of prohibitively high maintenance costs and the loss of their champion to pastures new. There is structure, there is a lively use of a mocking framework, and above all, pages and pages of assertions, many of which boldly claim that the system should behave in ways that it patently no longer does. We who are left know what these tests cost, but we cannot tell what value they bring, and thus cannot make a case for bringing them back to life. We are, essentially, disinherited. [1].
Many teams have an Old Test Suite.
It turns out that maintaining automated tests over a long period of time is hard, particularly when the people who wrote them are no longer around. A key technique, as in all programming, is to separate out levels of abstraction and remove duplication, with the aim of capturing the essence of what the test is about, rather than the details of how it is implemented. Without these, it is very hard to evaluate what value the tests bring if you didn't write them yourself. But our Old Test Suite seems to have invested significant effort to keep incidental details out of the way and remove duplication, and yet it has still died, and its tests still don't really capture their "essence" from my current standpoint.
So what went wrong? Undoubtedly the people involved could have communicated better. But perhaps all those assertions are also part of the problem.
The Problem with Assertions
Suppose we have written a function that adds two numbers together, and we wish to test it. So we choose some test data, say the numbers 1 and 2, and we apply the function to them.
What answer should we expect? Well, 3 of course, so we write an assertion at the end of our test:
int x = 1; int y = 2; int result = addNumbers(x, y); assertEquals(result, 3);
This - assertion based testing - is a great way to test the addNumbers function and is the basis of most test automation around today.
Suppose now that we have written a booking system for an airline, and we wish to test that it is possible to make a booking. So, we write scripts to set up our database with some flights and some users, then write a script to fire up a browser and click on the relevant controls in the UI. When we are done, we come to write our final assertion that everything worked correctly. So, what answer should we expect here?
The question is absurd. An airline booking system doesn't exist to provide "answers", it manages information, as most systems do. It is apparent that we should expect many things to happen, in the database, in the UI, in log files. Trying to boil them down into a single assertion with a numeric answer is a bit like asserting that the meaning of life is 42.
It is of course possible to assert that one row has been added to the "bookings" table in the database, or that the destination city appeared on the screen at some point, or indeed to write any number of other plausible assertions that are true of the current implementation. But this is extremely difficult to do well. Either we assert something simple, and probably miss most of the bugs that could be demonstrated by the workflow, or we write lots of complex assertions, trying to identify different aspects of the current behaviour that are correlated with having successfully made a booking. Our Old Test Suite above took this second approach and reality has simply moved on and left it behind.
Note also that there are plenty of things that definitely should *not* happen, for example unrelated database tables should not be changed, and no ponies should dance across the screen while we are trying to book our flight! Assertions are however almost always positive in sense: they require particular things to happen, mainly because it's clearly impractical to try to guard against all conceivable negative outcomes. If you see an assertion guarding against dancing ponies, it most likely exists because this outcome has already happened in production...
Assertions work well when the results of a test are well-defined, stable and simple. This is often true in the world of unit tests, and particularly the kind of simple unit tests that often feature in testing literature. But when the result is complex, containing a lot of information, a list of hand-crafted assertions is a very time-consuming and un-agile way of handling this. When the result is heavily dependent on the current implementation in a changing world, assertions also quickly become an unwieldy tool. It is fundamentally very difficult to create abstraction layers and remove duplication in long lists of assertions, by their nature they tend to be tied to particular tests and concern themselves with details.
The tagline of the Agile movement has always been to embrace change, and to try to create practices that assume that change is normal. Assertions don't really do that, they contain truth-claims, implicitly true until further notice. They create the illusion that tests can be a solid, unmoving rock to lean on in the storms of changing systems and requirements. In practice, if requirements or designs change, so must tests. What is needed is an approach to testing that assumes that the tests will need to change, and makes that process as straightforward and safe as possible.
Approval Testing
All of those many "potential assertions" that we could be writing represent aspects of the behaviour of the system. Every time anyone changes any code in the system, that behaviour could change, potentially destructively, potentially in subtle ways. Approval Testing is an approach to testing that focuses on capturing and storing this behaviour, presenting these behaviour changes, and allowing the team to react to them.
In general, a three-way choice is presented for each behaviour change: Reject, Approve or Ignore. "Reject" is the most familiar option, when the change is clearly undesirable, we go and fix our code, as if an assertion had failed. But often behaviour changes in the system are desirable of course, and in that case a convenient way to "Approve" them is provided. This will essentially ensure that future comparisons are made against this newly approved behaviour instead of against the previous behaviour. Sometimes changes just aren't relevant or interesting, and in that case there is a way to "Ignore" them and prevent future similar changes from being flagged at all.
You may have heard the terms "Golden Master Testing" or "Characterisation Testing". These are examples of Approval Testing, normally used in the context of legacy code. Recently there has also appeared "Snapshot Testing" as yet another term for more or less the same thing.
Blacklisting and Whitelisting
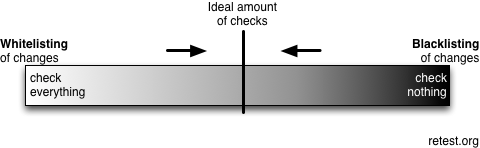
For a given scenario, on a scale from "checking nothing" to "checking everything", it is clear that the first extreme is maintainable but ineffective. That is to say, no maintenance effort is required if nothing can fail, but no bugs will be found. The second extreme tends to be unmaintainable but effective - the large amount of checks finds many bugs, but the maintenance effort will also be unacceptably high. Then there is a sliding scale between these extremes, but as a general rule, effectiveness and maintainability are inversely correlated.
Writing an assertion-based test starts from "checking nothing" - the state of your test when you have triggered the code under test but have no assertions. You are then required to think up possible behaviour changes that should be blacklisted, essentially adding assertions to the test to constrain the acceptable outcomes. The more complex the scenario, the harder this is to do effectively.
There is no mechanism to tell you when you are done: each new assertion makes the testing more effective but also less maintainable. Deleting existing assertions is psychologically difficult, so having too many assertions often isn't addressed until it's got way out of control, as in the case of our Old Test Suite above. Missing assertions (that should have been written but weren't) just let unacceptable changes through, and the only way of discovering this is to wait for those bugs to be discovered some other way downstream, typically by manual testers or customers.
An approval test, in contrast, starts from the other end of this scale, "checking everything". The starting assumption is that only the exact current behaviour of the system is acceptable, and by an iterative process of whitelisting (ignoring) certain kinds of changes, aims to arrive at a situation that hits a happy medium between maintainability and effectiveness.
A key point is that this process is largely self-correcting - the "definition of done" for the whitelisting process is that you've done enough when the maintenance effort feels manageable. It is done "on demand" as and when uninteresting behaviour changes show themselves, rather than needing to be done when the test is written. It is much easier to do this well, because the question "is this behaviour change interesting?" is much easier for the average person to answer than "what are all the possible failure modes in this scenario?"
Note also that such whitelisting does not need to be done via program code, not even "pseudo-code". Approval Testing tools can and do present these choices in such a way that only domain knowledge is required to take the decision. Assertions, in contrast, require some kind of concept of a "variable" to assert against, and this process usually ends up looking a lot like programming, however much syntactic sugar is piled on the top.
Legacy Code
Much of the literature on testing (and indeed software in general) assumes that you are starting from scratch and that all code and tests will be written within the current team and its process by competent team members communicating regularly and effectively. In practice, much of the industry has to deal with the experience of maintaining and extending code that was apparently written years ago by reckless incompetents who didn't have a process and probably didn't talk to anyone. And certainly didn't think about how the whole sorry mess would be tested.
In this situation Approval Testing is often the only way to retrofit tests after the fact, at least without excessive expense and risk.
Legacy code usually doesn't even have a "correct behaviour" - it does what it does and its users (and calling modules) have long ago got used to all of its bugs and weirdnesses. You can't approach it by swinging the axe and reasoning about how it ought to behave. Even fixing apparently obvious bugs needs to be done with great care. The important thing is to keep a close eye on the behaviour and make sure that if you change it at all, you do so deliberately and after careful consultation with the affected parties. This is exactly how Approval Testing approaches the problem.
Once you have some Approval Tests in place, you then have a measure of control and can then develop other kinds of tests if you wish, as is sometimes recommended. You may find, however, that tests written in this way are a convenient way to test legacy code also in the long-term, and that the effort required to retrofit other kinds of tests afterwards just isn't worth it, especially if you don't have the ambition to rewrite all of the code.
Potential downsides
Of course, there can be disadvantages to testing this way also. Possibly the most famous one is known as the Guru Checks Output Antipattern. Indeed, some critics regard this as almost an alternative name for Approval Testing (or Golden Master Testing). [2]
The basic argument is that Approval Tests are not "self-verifying" because failures have to be assessed by a human ("the Guru") in order to take the decision whether the changes are to be Rejected, Approved or Ignored, and that the potentially large amount of information being verified can lead more frequent failures and a greater maintenance burden.
There is an element of truth to this argument. Certainly at first Approval Tests will generate more "noise", until you've Ignored all the things that you discover you don't care about. But as you Ignore more things, the amount of maintenance required should decrease. By continuing to add more "ignores" until the maintenance is manageable there is a built in way to handle this problem.
Good tool support is key, that can store the approved behaviour in an organised way and automate the "approve" and "ignore" operations in a convenient way. (See the appendix below for some suggestions). With decent tool support, the vast majority of approve/reject/ignore decisions can be taken by anyone moderately informed about the system - no "Guru" is needed. With an Agile process in place, small decisions about the behaviour changes caused by individual code changes are managed on a regular basis, avoiding the need for a "Guru" to assess a large, complicated change all at once.
Note that any non-trivial assertion-based test isn't "self-verifying" in any meaningful sense either, because as we've seen, correct behaviour of systems can and does change, and often the only criteria for correctness is the current whim of the user or product owner. At some stage a human will need to assess a failing assertion and decide if it needs to be removed (Ignored) or rewritten (Approved), or some code needs to be fixed (Rejected), and that nearly always requires a programmer, if not a Guru.
Maintenance efforts may be less frequent with assertion-based tests but they also tend to be more complicated when required, and can become fatally expensive, as we've seen with our Old Test Suite.
Conclusion
In short, Approval Testing is a human-centred approach to writing tests that asks the kind of questions people are good at answering, replaces up-front effort with iterative adjustment, and has a built-in "definition of done". These are exactly the kinds of things the Agile movement has been promoting for nearly two decades now.
Appendix: Approval Testing Tools
There are now many tools that support this kind of testing. We present a selection here:
TextTest
First released in 2004, TextTest is a well-established and mature tool in this space. As the name suggests, it works by representing system behaviour as plain text files, and comparing them using graphical difference tools. Approving a change is as simple as overwriting the affected files with newer files. Ignoring changes is done with a filtering "mini-language" based on regular expressions.
TextTest is data-driven: the expected usage is to vary the data provided to the system under test but not to write test code for each test. The system under test is run from the command line, meaning that a single test harness script typically needs to be written to wrap it into a self-contained run that produces some useful text files that can then be compared. A typical test harness to test a server might then do something like
- Create a database, populate it with appropriate (minimal!) data for the test
- Start the server under test, connected to the database above
- Send it some input (stored in a test data file in the test)
- Write a file with whatever data the server returns
- Write another file listing any changes that occurred in the database
- Stop the server and drop the database
The aim is for such a run to be completely self-contained in a sandbox directory, with files only written in that place, and for the tests to be fully independent, not relying on any global resources and tearing everything down when they are done. What is lost in speed is gained in ease of parallelism, which in today's world is generally more important.
It is also possible to test UIs this way, by combining TextTest with a GUI automation tool such as Selenium or Sikuli to drive the UI.
TextTest screenshot. image source: http://texttest.sourceforge.net/
Approvals
The 'approvals' family of tools is designed to augment a unit test framework with approval testing capabilities. It is available for a wide variety of programming language and unit testing tools. You write the first part of the unit test as you would normally, but replace the "Assert" part with a call to the Approvals library. The text that you approve is often the output from a call to "toString" on the object under test, so you may have to add extra production code to print something sensible (ie not an object reference). It also works with screenshots of GUI elements or any custom string you have your code produce. When you approve the text, it's stored in a file alongside the test code, that is named the same as the unit test case that uses it.
This tool is particularly useful when adding unit tests to legacy code. It makes it easy for you to make detailed assertions, and it also has a really useful feature called 'all Combinations'. This allows you to do data driven testing of all possible combinations of arguments you specify to a method under test. If you use it together with a coverage tool you can quickly get a lot of code under test, with quite detailed assertions about behaviour. The amount of code needed is very small and a large file of approved text doesn't tend to cause a prohibitive maintenance cost.

Approvals screenshot. image source: http://approvaltests.com/
ReTest
ReTest adopted an approval testing approach when its team tried to introduce AI into software testing. Since failures are in the eye of the beholder, an AI has a hard time to distinguish the correct behaviour of a software system from incorrect behavior. Therefore, automated testing is very hard to achieve and will continue to be so in the foreseeable future. Autonomous test automation, on the other hand, can be achieved by combining AI-based intelligent software execution with approval testing for the GUI.
ReTest has gone to lengths to retrieve UI elements together with other relevant properties, such as size, color or font. This essentially replaces pixel-based comparison of a GUI-screenshot with a semantic-based comparison. It is thus much easier to ignore volatile information (e.g. if the color changes depending on operating system) or mass-accept identical changes. ReTest is now implemented for Java Swing GUIs and its team is currently working to define an open source API and implement that API for both web and mobile.
The vision behind ReTest is that new features or changes to existing features are extensively manually tested. Then AI takes over and creates Approval Testing-based regression tests that make sure that this approved behaviour does not change any more without anybody noticing.
ReTest screenshot. image source: http://retest.org
Jest
Jest is a tool from Facebook, that is written in JavaScript and specifically aims at comparing React components. Instead of rendering the graphical UI, one can use a test renderer to quickly generate a serializable value for the react tree and store that HTML snippet as a snapshot file. In later executions, that snapshot file is then compared and updated. Due to it being promoted by Facebook and react, it has become widely adopted in that setting.
Jest screenshot. image source: https://facebook.github.io/jest/
Pixel-based comparison tools
There are many tools that provide pixel-based comparison of a screenshot of the application GUI, dubbed "visual regression testing" tools. Some examples are Applitools, Appraise and BackstopJS, but there are many more. Being pixel-based, these tools are usually only applicable to the visual output or display of a system, in contrast to, e.g. a database or XML response from a server.
References
1. This section is loosely inspired by the poem "Disinherited", by the Irish poet Pádraig Ó Broin
2. Note that, although "Guru Checks Output" is often used to refer to this kind of testing, it originally referred to a human having to check the entire output manually each time a test was run, which is obviously much slower and more error-prone than what we are proposing here. A more accurate name would be Guru Checks Changes.
Further Reading
- Automated Testing Strategy in a Microservices Architecture, part 1
- Approval Testing with TextTest
- An Introduction to text-based test automation and the TextTest tool(slides) (pdf)
- Exploiting ApprovalTests for clearer tests
- Expressive objects (slides)
- Assertions considered Harmful
- Introducing Appraise
- Can Approval Testing and Specification by Example Work Together?
Related Software Testing Resources
Click here to view the complete list of Methods & Tools articles
This article was originally published in May 2018
|
Methods & Tools Software Testing Magazine The Scrum Expert |
|
Discover the best available Open Source Project Management Tools (Gantt, Scrum, Kanban) Explore a list of Free and Open Source Scrum Tools for Agile Software Project Management |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


