|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Parallel Development Strategies for Software Configuration Management
Tom Bret, Confluence Systems Ltd
Abstract
Software project managers routinely face the challenge of developing parallel configurations of software assets. If not identified and planned for in advance, the complexity introduced by parallel development can derail even an otherwise well-managed project.
This article describes business situations where parallel development is necessary and examines strategies for configuration management in each situation. "Patterns" are identified which allow different projects with similar characteristics to be managed in a repeatable way, and make it possible to carry forward a body of knowledge and experience from one project to another. Patterns may be combined or nested to deal with complex scenarios. Parallel development potentially needs to be managed at multiple levels within a software asset repository, recognising that different products and components may have their own independent development lifecycles.
What is Parallel Development?
Many software projects, especially in their early stages, follow a strictly linear development progression in which each successive version of the software is derived from, and increments, the previous version. The configuration management of such a project is straightforward, since in general there is just one "latest and greatest" version of the software, which forms the context in which all development work takes place.
Parallel development occurs when there is a need for separate development paths to diverge from a common starting point, so that there is no longer a single "latest and greatest" version, but instead two or more concurrent "latest" configurations (often called variants) where new development is carried on. Also implicit is the potential need for the divergent development paths to converge again. This means that any strategy for development branching should also take into account the process for merging.
Why Parallel Development?
There are many reasons why parallel development may be necessary for a project. These include:
- Release preparation
- Post-release maintenance (segregated from new development)
- Tailored or customer-specific software
- Segregation of work by different development teams or individuals
- Segregation of work on different features
- Deployment of different software variants into different environments
Macro and Micro Parallelism
Parallel development can occur at the level of a single file or other configuration item (micro level) or at the level of an overall project configuration (macro level).
Consider the case cited above regarding "segregation of work by different development teams or individuals". If different developers need to make changes to the same configuration item for different purposes, this can often be handled by short-term branching at the micro level. The second and subsequent developers to complete their work would be responsible for merging to maintain the integrity of all changes to that configuration item, but still within a single overall development context.
In the case of changes involving more than a small number of configuration items and/or timescales longer than a few hours, parallelism at the micro level would rapidly become unworkable due to the large number of ad-hoc merges; teams or individuals waiting for completion of each other's merges; and confusion over the merge status and correct "latest" version of each configuration item. In this situation it makes much more sense for each team to work with its own different "latest" configuration of an entire project (macro-level parallelism). Behind the scenes, branching of individual configuration items still takes place, but a good software configuration management (SCM) tool should handle this (more or less) transparently to the user. Merging would be deferred until a suitable development milestone, when a batch merge of all the desired changes may be performed to result in a single "latest and greatest" version once more, forming the basis for the next development cycle.
Brad Appleton [1] refers to this as "file-oriented" and "project-oriented" branching, and summarises as follows:
"Most VC [version control] tools supporting branches do so at the granularity of a lone file or element. ... This is called file-oriented branching."
"But branching is most conceptually powerful when viewed from a project-wide or system-wide perspective; the resultant version tree reflects the evolution of an entire project or system. We call this project-oriented branching. "
Fundamental for the capability of a tool to support macro-level branching is the capability to save and reproduce successive versions of the entire project configuration on any branch, known as baselines or checkpoints.
The remainder of this article will deal with macro-level branching and the business situations to which it can be applied, using a modern SCM tool with good support for macro or project-oriented branching.
Frequently Experienced Problems
The assertion, made earlier, that "the complexity introduced by parallel development can derail even an otherwise well-managed project" is backed up by anecdotal evidence of problems experienced on software projects where branching and merging has been poorly planned or poorly controlled.
- Project granularity: failure to allow for a separate lifecycle of sub-components
Product released with immature component code, or component changes interfere with product release cycle - Failure to segregate maintenance fixes from new feature development
New features "leak" into production code when not fully QA'd and/or not paid for by customers - Failure to segregate custom code from base product
Custom features accidentally released when not paid for and/or in violation of confidentiality - Over-complex branching model
Excessive amount of effort spent in merging and maintaining branches; developer confusion about which branch they should work on - Failure to track compatible sets of changes and apply them consistently during merge
Broken build or non-working features after merge - Failure to anticipate the need for parallel development and to plan early
Inappropriate tool selection and/or repository design becomes "locked in" in the early stages of the project and only becomes a problem when it is too late to remedy without excessive cost, effort and/or delay
Careful and appropriate design of the branching model is critical to success - as expressed by Mario Moreira [2]:
"A branch and merge strategy should be designed prior to creating branches to first ensure that branching is needed and secondly to ensure that the branch structure under consideration will work for the project."
Tool selection can also be critical, since development teams may be forced into one or more of the above problem situations by constraints of the configuration management tools they are using. Tool selection is typically done early in the development project lifecycle, and it is important to think ahead, since branching requirements may typically only arise later in the lifecycle: for example, once post-release maintenance comes into play after the first production release.
Introducing SCM "Patterns"
A key factor to help achieve a successful design is the use of patterns. A pattern is an established engineering solution for a certain class of problems: for example, in civil engineering, the "river crossing" class of problems may lend itself to solution patterns such as "bridge", "ferry" or "tunnel". The engineer will be guided to a choice of pattern by parameters such as width, depth and flow speed of the river, type and density of the expected traffic, and so on. In both choosing a pattern and subsequent execution of the solution, the engineer can draw on a body of prior experience with these patterns.
Most readers will be familiar with the well-established concept of patterns in software engineering. The use of patterns is becoming established in Software Configuration Management [3] though less mature than in software systems analysis and design, it is still a very useful and instructive approach.
We now discuss various patterns that can be applied in different situations where parallel development occurs. It is worth noting that these patterns may - indeed should, be adapted and/or combined (with each other or with other SCM patterns) to achieve the best solution fit with a particular set of development project constraints and requirements.
The treatment of patterns in this article is somewhat simplified compared with Berczuk & Appleton [3], [4]; where appropriate, cross-references are given to the Berczuk & Appleton nomenclature [4].
Pattern: Branch per Release
[Berczuk & Appleton: Release Prep Codeline]
Probably the most frequently encountered motivation for parallel development, mentioned several times already in this discussion, is the need to segregate post-release maintenance from ongoing development targeted on future releases. Taking this a logical step further, we could (or indeed should) segregate the Pre-release fixes in the same way. The optimum point at which to diverge a release configuration from the ongoing "mainline" of development would be at the point of "feature freeze", when the decision is taken not to include any more features in the release being planned. From this point onward it becomes important that no further feature-enhancement code leaks into the release and that only changes necessary to fix existing features are applied to that configuration.
A convenient simplification is to continue post-release maintenance on the same development path as the release preparation (rather than using a separate release branch) - the successive release candidates, releases and patch releases simply being incremental checkpoints along the same development path.
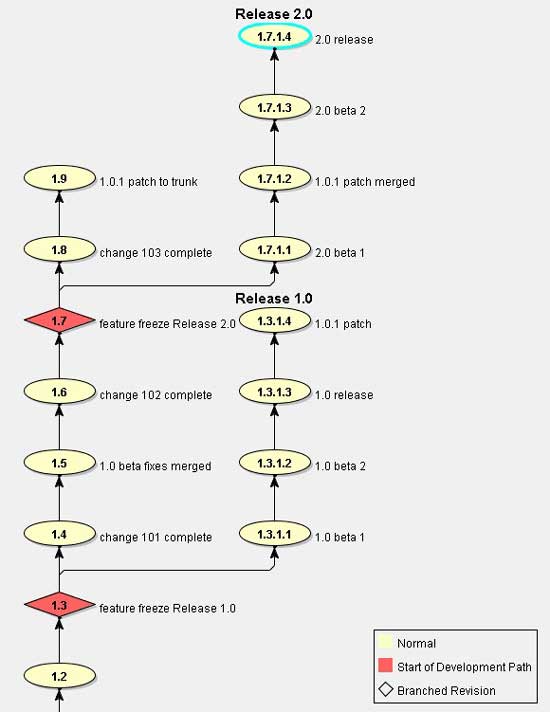
In the "project history" diagram above, we see that all the main feature changes are implemented on the project "trunk". (This corresponds to the Berczuk & Appleton Mainline pattern.) A checkpoint has been taken on completion of each change and labelled with the change number (change 101, 102, 103).
In parallel with this, fixes during release preparation and post-release maintenance have been made on release branches that diverge from the trunk at each feature freeze checkpoint. Each checkpoint on the branches would correspond to a release candidate, beta or patch build. (The illustration has been simplified and in real life there would probably be many more checkpoints, fixes and changes!)
A criticism sometimes levelled at this pattern is that fixes need to be made in more than one place: any fixes made on a release branch are likely also to be needed on the trunk (mainline), and possibly on other release branches if multiple releases are active. This is true but is mitigated by the following factors:
- The fixes which need to be merged will generally be relatively small code changes and therefore easy to merge
- The (generally much larger) feature changes do not need to be merged at all
- In practice, some of the fixes will have been rendered obsolete by other changes on the trunk and will not be required
Usually it is better (both for quality and productivity) to design for smaller merges, since merging can be a time-consuming process and bears the risk of introducing errors.
Pattern: Branch per Change
[Berczuk & Appleton: Task Branch]
The motivation for using a "Branch per Change" pattern has already been discussed above under "Macro and Micro Parallelism". To summarise, when different development teams are engaged in large and complex changes that may involve conflicting changes to the same configuration items, it may be desirable to isolate them from each other using different development paths. This means they are each able to check-in interim versions of their code without adversely affecting each other (as might occur if they were both using the same "mainline"). Merging back to the trunk, or mainline, is deferred until each change is complete and the merge is "batched", meaning that all the related code changes are merged at the same time so that the mainline remains consistent. A good SCM tool should have the capability to track which code changes are related to each other and also to initiate the batch merge of those changes.
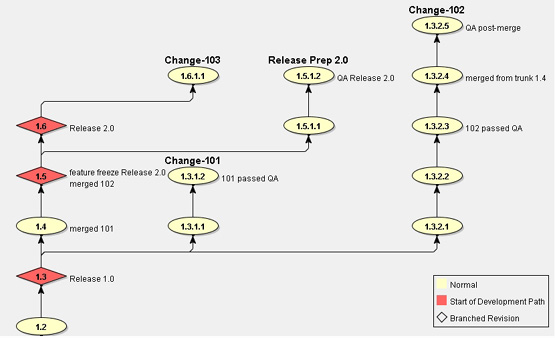
This time in the project history diagram we see, diverging from the "Release 1.0" checkpoint on the trunk, two separate branches for "Change-101" and "Change-102". On completion of each change, the code is merged back to the trunk, resulting in a new checkpoint ("merged 101" etc). After feature freeze and use of a release preparation branch, the cycle restarts from "Release 2.0" and "Change-103".
The main difficulty with using this pattern is that the amount of code to be merged is much larger than with "Branch per Release"; this is because each merge involves the entire code for some new feature, rather than just a bug fix where the code changes are often quite small.
Also, if this pattern is rigidly applied - for example, by restricting developer access on the trunk so that developers are forced to work on branches - then it imposes a large procedural overhead on even a very small and simple change. This could have an adverse effect on productivity (due to the disproportionate amount of time spent performing merges and verifying the merge results) as well as causing a proliferation of branches that could lead to confusion. Arguably, for most development teams, it would be preferable to create task branches only for changes of long duration or which are known to conflict with other changes already in progress, and to allow simpler changes to be done on a single shared "mainline".
Anti-Pattern: Good Code on Trunk
If a pattern describes a known engineering solution to be emulated, an "anti-pattern" could be defined as describing a known engineering pitfall to be avoided! Consider the - superficially quite convincing - concept of only allowing "good code" (i.e. passed by some QA process) on the project trunk. This is often found in conjunction with the "Branch per Change" pattern and in fact is illustrated in the "Branch per Change" diagram, above.
The problems here are:
- The excessive merge workload and the effect this has on developer productivity;
- Over-restrictive process interfering with progress of the development team;
- Additional QA overhead; and
- The fact that merge outputs are generally not reliable anyway, certainly requiring verification and often necessitating rework.
Looking again at the diagram, we see that Change-101 has been completed first and may be merged straightforwardly back to the trunk. Change-102, when completed, cannot be merged without either losing the Change-101 updates or introducing non-validated merge results onto the trunk. To comply with the "Good Code on Trunk" principle, the only option is first to merge the Change-101 code to the Change-102 branch, repeat the QA process (verifying that both the Change-101 and Change-102 features still work) and then to perform a second merge onto the trunk. Worse still, no other changes may be merged to the trunk while this second merge is pending, because this would invalidate the QA for Change-102, so the project progress could be held up for possibly several days while this is ongoing. If we imagine a large project with say fifteen parallel change branches instead of two, we can see that the extra effort and complexity would become overwhelming.
Pattern: Branch per Environment
[No direct equivalent in Berczuk & Appleton]
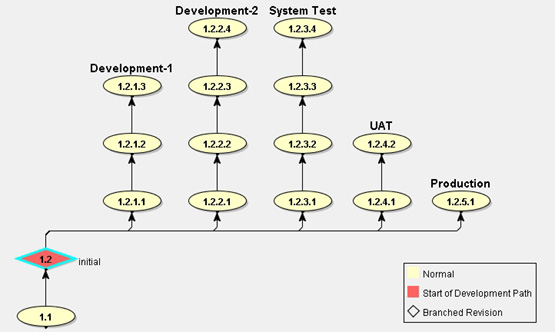
A situation often encountered, especially with software systems being developed for "in-house" use, is the requirement to migrate software into successive different environments. Typically this starts with a development environment (sometimes several different ones, allowing for segregation between work by different teams) and moves on into system test, UAT (user acceptance test) and production environments.
By modelling each environment with a parallel "development" branch in the software repository, it is possible to harness the CM tool to assist with:
- Packaging and deployment of migrations between environments;
- Status accounting of current configuration in each environment;
- Access control to different environments; and
- Traceability of changes as they move through the environments (for instance, so that testers which fixes and features are available for test).
Composite and Nested Patterns
The patterns presented here are abstractions and simplifications of situations encountered in real-life software development projects, and represent only a fraction of the possible patterns that could be identified. When designing a configuration management implementation, it is important to maintain flexibility to match the needs of the project, to use patterns for guidance but not to be constrained by them, and to adapt or combine them as appropriate. The following are some examples of how this might be approached.
Branch per Release nested at component level. A code repository is organised as a number of products each made up from some combination of components. Products and components have their own independent release cycles and each is controlled using a Branch per Release pattern. Different products (or successive releases of the same product) may utilise different releases of the same component.
Branch per Release adapted for tailored customer code. A similar structure to the above could be used to manage the delivery of tailored versions of a core product. In this case the core product would be treated as a component (or set of components), and customer-specific code would also be segregated into components. A "container" project for each customer would not hold any actual code, but just a set of pointers to the correct versions of the core and custom components. (This depends on the use of an SCM tool with appropriate support for component inclusion or "sharing".) The design objective here should be to avoid a proliferation of customer-specific branches within the actual components themselves.
Composite of Branch per Release with Branch per Environment. The development of a software system follows a Branch per Release pattern and each release is deployed into successive environments using a Branch per Environment pattern. Each release branch spawns its own sub-tree of environment branches.
Composite of Branch per Environment with Branch per Change. A Branch per Environment pattern is used, but additionally a Branch per Change pattern is superimposed on the development environment. Development is not a single branch, but a sub-tree of change branches.
Conclusions
It is hoped that this article has encouraged software project managers and SCM practitioners to take a fresh look at the issues surrounding parallel development, and the engineering solutions by which they can be addressed. Careful analysis of the project requirements at an early stage, coupled with appropriate tool selection and a disciplined development process, can avoid many of the difficulties which have traditionally beset branching and merging within software repositories.
To conclude - some key points to keep in mind:
- Plan early
- Use patterns
- Get the right tools
- Merge little & often
- Batch merges of related changes
- Avoid excessive complexity
- Be creative!
References
- Brad Appleton (Motorola Network Solutions Group) et al
Streamed Lines: Branching Patterns for Parallel Software Development
www.cmcrossroads.com/bradapp/acme/branching/#StreamedLines - Mario Moreira (Fidelity Investments Systems Company)
ABCs of a Branching and Merging Strategy
CM Crossroads News, November 2003
www.cmcrossroads.com/newsletter/articles/mmnov03.pdf - Steve Berczuk with Brad Appleton
Software Configuration Management Patterns: Effective Teamwork, Practical Integration
Addison-Wesley, 2002 - Steve Berczuk with Brad Appleton
Software Configuration Management Patterns Reference Card
www.scmpatterns.com/book/refcard.html
More Software Configuration Management Knowledge
- Lean Configuration Management
- Build Patterns to Boost your Continuous Integration
- Continuous Delivery Using Build Pipelines With Jenkins and Ant
- Open Source Software Configuration Management Tools
Click here to view the complete list of archived articles
This article was originally published in the Summer 2004 issue of Methods & Tools
|
Methods & Tools Software Testing Magazine The Scrum Expert |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


