|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Code Generation for Dummies
Matthew Fowler
New Technology / enterprise, http://www.nte.co.uk
Introduction
When I was a lad, code generation referred to the final phase of a compiler. Having digested your source code, the compiler would pump out the "code" for the target machine. At that time, "machine" meant a CPU instruction set - so this was machine operation code being generated.
Having learnt all compiling languages like FORTRAN and PL/I, my second job - way before the PC, let alone the dreaded CASE tools - was to build a code generator to create CRUD applications. Back then, it was practically unheard of to do this. These days, 'code generation' is so well established that Wikipedia has a new meaning for it - i.e. "source code generation" rather than "machine code generation"... and it has all sorts of new terms and ideas swirling around it.
It turns out that there are fundamental similarities between the old and new versions "code generation, and comparing them helps us understand the similarities. It is a good place to start to understand today's code generation landscape.
I'm going to start by drilling down into old "code generation" and compare it relationship to DSLs and modelling ... and establish the similarities between all three. Using this common basis, I'll explain the reason behind the recent fashion for "XML with everything" and the de-facto standard approach to defining languages in XML. Finally, I will actually describe the first steps in code generation.
Something Old
A compiler runs through a number of phases in processing an input language program:
- lexical analysis , which turned a character stream into a 'token' stream.
For example, if we write "i = 0;" in C or its successors, this turns into the tokens
[IDENTIFIER(i)] [EQUALS] [INTEGER(0)] [SEMICOLON].
- the preprocessing phase. Some languages, notably C, have preprocessing that works on tokens, so they had to go next. Preprocessors could include source files, paste tokens together or turn arguments into a complete new sequence of tokens.
- parsing , which analyzed the tokens according to the grammar of the language and produces an Abstract Syntax Tree (AST): the "abstract syntax" is the grammar free of syntactic confetti like ';' or '.', and it's a tree because there is one root - the program - with the contents of the program beneath it as AST nodes. In an OO world, the AST nodes will all be derived from a Node base object but have specific types for the grammatical constructs - IfStatementNode, IdentifierNode, IntegerConstantNode.
- semantic validation and optimization. This worked directly on the AST, checking out that it made sense (e.g. referenced variables were declared if necessary) and optimizing it.
- finally - at last - the actual code generation bit, which wrote out the machine code or some equivalent intermediate form.
The two main tool-sets I know of to help with compiler construction are the LEX/YACC pair from UNIX and ANTLR. Both of these help with the lexical and parsing phase, and use a specification of the syntax/grammar to do their work.
In computing terms, many of the ideas about compilers are not old - they're positively ancient. Descriptions of syntax still derive from BNF (Backus Normal/Naur Form), dating back to the 1950's; parsing techniques were regularized in the 1960s.
Summary for dummies:
- Language processing, including code generation to machine code, is well-established and old hat. The main structural phases are lexical analysis, parsing and code generation.
Something New?
Now, if we're fashionably up-to-date, we'll shun general-purpose programming languages ('GPLs') like Java or C# and do development by creating a model or writing a program in a Domain Specific Language ('DSL'). So is this new? Let's look at what happens in language terms when we use a DSL, taking regular expressions as an example.
The "regular expressions" DSL was one of the languages built in the 1970's to assist UNIX developers. The initial raison d'être for UNIX was typesetting at Bell Labs (it took a slight detour along the way) so mini-languages were created around the notion of text manipulation - sed, awk, grep and regular expression's are the ones that roll off the tongue.
A regular expression is a series of commands to find a substring of a larger string based on its shape rather than the exact text - so it was pattern matching for text. A regular expression is made up of a number of actions - basically telling the interpreter what to do to find the string. For example:
^ Match the beginning of the line - i.e. what follows must be at the start of the line
21: Match the string "21:" exactly.
[a-z] A range, given in the [] brackets, in this case it is from a-z.
[^W] Match any character except upper-case W.
+ Using the preceding regular expression, match one or more of them.
. Match any character.
* Using the preceding regular expression, match zero or more of them.
Most modern editors allow you to search files for a regular expression and they're very useful in certain situations. For example, we've done a lot of looking at logs recently. In thousands of lines, we often want to find where the initialization is finished for a particular run, so there is a line like:
21:19:49 132.940.838 Brokerage getProxy Working at 21:19:49
Searching for an exact string won't work here because the timestamps change. To find where the system started working around 9pm, we can do a search in the editor using a regular expression like
^21:[^W]+Work.*
The '^' matches the beginning of the line and then the characters "21:" select the 9pm timeframe. The [^W]+ skips one or more characters that are not 'W', followed by "Work". '.*' matches the rest of the line.
Let's come back to the idea of a regular expression as a series of commands. This is a fundamental pattern in software: we're telling a processor what to do. You could also write the processor in Java, in which case you would control it using an API. Something like this:
MatchSequence matcher = newMatchSequence()
.startLine()
.literal("21:")
.oneOrMore( new AnythingBut("W") )
.literal( "Work" )
.restOfLine();
(If you know regular expression, please forgive the conversion of '.*' into 'restOfLine' - it would be strictly correct as a 'zeroOrMore' plus 'anyCharacter' combination.)
While lengthy regular expressions demand patience and humility to debug, in their domain (pattern-based text searching) they are sharper and faster than the general-purpose alternative. This is characteristic of a good DSL: its conciseness aids thinking because there is a direct correspondence between how an expert thinks and the symbols of the DSL. This means that the form (the syntax and its resonance with the domain expert's concepts) and context (for example, the spreadsheet presentation of Visicalc) are vitally important to the success of a DSL. The rules for writing correct programs are often called the concrete syntax; and it has its own rules of composition just as the abstract syntax does.
As you have probably guessed from the section title, the processing of DSL's proceeds exactly as for general purpose languages. The lexical analysis splits the text based on the special characters:
STARTLINE TEXT LEFTBRK UPARROW CHARS RIGHTBRK PLUS TEXT DOT START ^ 21: [ ^ W ] + Work . *
The parser creates an AST that is similar to the Java code given above:
RegularExpression
|
_________________________________________________________
| | | | | |
StartLine Literal("21:") OneOrMore Literal("Work") RestOfLine
|
AnythingBut("W")
I find it helpful to think of the AST as the in-memory representation of the instructions for the next processing step. We're interested in code generators, but the regular expression handler in my editor is interpreted; the same AST works equally well. Each node in the AST is an instance of a class, with qualifying attributes (e.g. "21:") and possibly children - for example, the OneOrMore class must have something to work on, which is represented by a child instance.
Generalizing from this example, we use the following terms about abstract syntax:
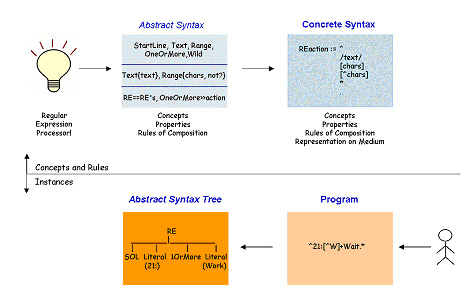
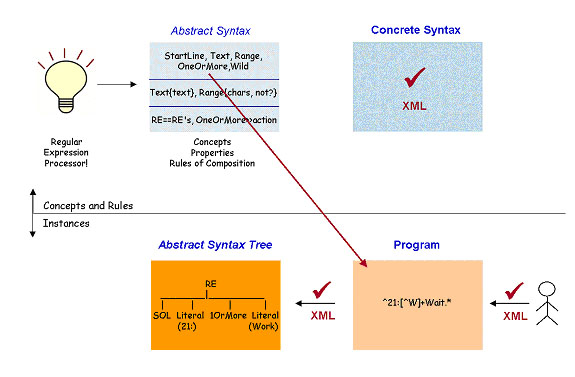
The top half of the diagram is about the design of the language. The language creator has a bright idea about a processor for a domain, which he or she elaborates as follows:
- The domain is based on some concepts (e.g. start of line) and either a description of information or operations to do on those concepts. For the regular expression language, the "operation" is implied in all the AST nodes - they all request a match of the string.
- Concepts can have some attributes to supply additional information. For RE's, these are the string to match ("21:"), or the available character range.
- A program is a composition of concepts and attributes. For the processor to know what to do, the "OneOrMore" node will need a child expression. This sort of composition is apparent from the AST, but others are more subtle, such as not defining a variable with the same name twice.
This is the abstract syntax. The concrete syntax also has concepts, attributes and composition rules, plus the additional syntactic framework so it can be represented in a particular medium, such as the braces in the 'class {...}' construct for the written form of a program.
n the bottom half of the diagram, the programmer writes the program in concrete system which is transformed into an AST.
Summary for dummies:
- an abstract syntax comprises concepts, attributes and rules of composition
- a concrete syntax has the same elements as the abstract syntax, with additional markings to map the abstract syntax onto the program medium like a text file
- there's no difference in processing DSLs (Domain-Specific Languages) and GPLs (General-Purpose Languages); the difference is in the form and representation of a specific domain's concepts and actions
- the acceptability of a DSL in a particular domain is determined by its form and presentation (because the underlying concepts and compositions are likely to be similar between different DSLs for the same domain).
Models and Graphical DSLs
We introduced 'models' at the end of the last section, then promptly ignored them. Now it is time to return to them, and address the terminology minefield, which has generated much confusion and heat in the last few years.
To a lot of people, models mean "UML models". The problem with this for our discussion of code generation is that UML models have historically been more of a means of communication than a rigorous specification of what a program has to do. As our interest is in code generation, I will use the term "model" to mean something written in a Graphical DSL that is precise enough to generate code from; we could also be more precisely about the regular expression grammar and call it a Textual DSL.
There is a growing trend in the Microsoft and Eclipse camps to use "DSL" to mean "Graphical DSL", but this is strictly incorrect.
A graphical DSL has an editor with a range of objects that can be drawn on the modelling surface. Typically you can add names and other details on the drawn object; for a 'Class' we can add fields and methods for example. There are also relationships between the objects, often expressed as lines but sometimes by other graphic devices, like attachment or nesting one object within another.
Graphical DSLs provide picture symbols to represent the use of a concept rather than a text representation, presumably because 8-year-olds and business sponsors find these easier to understand. So, rather than writing "^21:[^W]+Work.*" or the AST equivalent, we might construct the graphical DSL as follows:
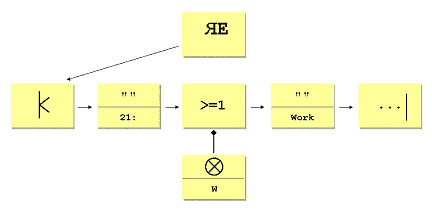
The graphical DSL can throw away the syntactical clutter, like '[]' for the character range, because it is implied by the symbol. However, the composition still has to be expressed somehow: in this rendering, it is explicit using arrow to imply order and the container symbol for the parent-child relationship. This is an example of concrete syntax mapped onto a graphical medium.
The above picture now looks very like the AST we drew out textually ... which was
RegularExpression
|
_________________________________________________
| | | | |
StartLine Literal OneOrMore Literal RestOfLine
("21:") | ("Work")
|
AnythingBut("W")
This is no accident: graphical DSLs allow users to use concepts, specify their properties and compose them into composite structures, just like DSLs do.
To briefly come back to UML models, and address their relation to graphical DSLs. The basic diagrams in UML modelling are DSLs in their own right, and in particular, the class diagram defines the information behind a C++ or Java program pretty well. At this basic level, "code generation" means converting UML to C/Java/whatever syntax; round-tripping means going back from code into a UML diagram. For example, this diagram
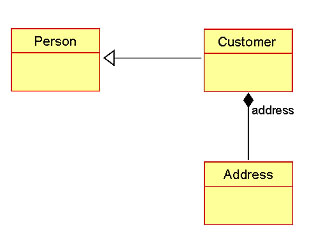
is equivalent to the Java code
class Person {
...
}
class Customer extends Person {
Address address; ...
}
class Address {
...
}
The class diagram of UML gives us another naming issue. Strictly speaking, it is a graphical DSL, but its domain is so generic - the description of classes of objects and their relations - that for most developers these days it is more like the data definition part of a GPL.
UML can be made more interesting by adding "profiles", which specializes all the modelling elements with a user-chosen "stereotype" name (e.g. in entity-relations modelling, we would use
<<entity>> and <<relation>> stereotypes ) and related tagged values like "description". For example, here is a stereotyped UML class and some specific tagged values for the stereotype:

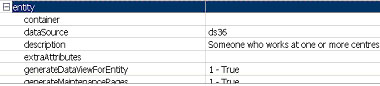
UML with stereotypes is the quickest approach to building a graphical DSL if your company has a UML tool, but it has drawbacks: the rules of composition that you would expect in a specialised graphical DSL cannot be specified - they will default to the UML rules; also, all the native UML information will be present in the modeler which is distracting if it is not relevant to the domain.
Graphical editors will have a serialization format, which is now a textual representation of the "program". For UML, this is XMI (XML Metadata Interchange), which is as baroque as its name implies. In Eclipse, models can similarly be serialized in XML dialects.
Summary for dummies:
- A model, or graphical DSL, uses a visual representation of its concrete syntax rather than a textual one.
- A model often suggests the structure of an AST, and for processing purposes a model is converted to an AST. So for code-gen, Model ==> AST.
XML and DSLs
The AST is the Great Divide of Code Generation: on our left is the expression of the intent in the source language - GPL or DSL, textual or graphical - and its transformation into an AST; on our right is the production of the code or whatever else we want to do with the AST. The AST is the central point of leverage.
Before we press on and talk about code generation, there are some important points to note about the AST. The starting point is that an AST is isomorphic to an XML document. Here comes the now-famous regular expression example, recast as an XML document using attributes for the embedded details:
<RegularExpression> <StartLine/> <Literal text="21:"/> <OneOrMore> <AnythingBut characterRange="W"/> </OneOrMore> <Literal text="Work"/> <RestOfLine/> </RegularExpression>
This XML could be a serialization of the AST ... or it could be written directly, with the XML dialect as the domain-specific language. Here's the entity-relational model we discussed earlier, recast as an XML 'program':
<entity name="Customer" dataSource="ds36"
description="Someone who works at one or more centres">
<attribute name="forename" type="String" />
</entity>
Developers have been using XML dialects as ad-hoc DSLs for some time. (While the "Domain" in "DSL" often has a connotation of "business domain", there is no reason this can't apply to technical domains, which is where this sort of DSL approach is used most.) In other words:
- the concrete syntax is mapped to XML syntax;
- the concepts are used as XML element tags;
- additional information is mapped to attributes;
- and the composition capability restricted to nesting which allows you to build up the AST tree.
This gives a natural or "bare" format we'll call AST-XML (although I'm sure someone's dreamed up a better name, if only I could find it): there is no additional syntax or meta-information in the XML model, making it is all a direct representation of the AST in XML.
So here is our "language creation process", with the XML short-cuts:
- the additional syntax in the concrete syntax is taken care of by XML
- the training of user's regarding the syntax is taken care of by XML if the user is a programmer
- the syntactical analysis for producing the AST is handled by standard XML tools
- the developer still has to define classes for converting the XML stream into objects.
XML-based configuration in the last few years has pretty much standardized on this approach - e.g. Spring beans definition, for defining beans to add into your program.
<beans ...>
<bean id="customerSimulator_ActionsBean"
class="com.equity.customer.CustomerSimulator_Actions"
init-method="Gsb_InitiatePulsesAndListener"
/>
</beans>
The intent of this program is to inject an instance of the CustomerSimulator_Actions class into the program. Spring Beans therefore is a DSL for defining class instances and their interrelation.
To understand how simple the AST-XML approach is, contrast it with other approaches that include this data, such as this from XMI version 1.1
<UML:ModelElement.taggedValue> <UML:TaggedValue tag="BusinessName" value="a3"/> </UML:ModelElement.taggedValue>
Most of this is describing XMI itself. The useful information would be written BusinessName="a3"' in AST-XML. The lack of superfluous stuff makes it easier to read and to transform from or generate code.
We cannot leave this subject without mentioning Ant's clever approach to implicit AST instantiation. Ant allows developers to write their own plugins as Java classes which are invoked by XML in the build file. The normal approach to converting XML elements to model objects is to use SAX to read the XML and then instantiate objects to represent the XML elements.
Instead, Ant uses implicit instantiation using introspection and naming conventions, which works as follows.
There is an AST node for regular-expression matching condition - i.e. there is a <matches> element in the XML.
This can have a nested element <regexp>, which defines the RE to match. If the class for the <matches>
element is Matches, then for this to work it must have an addRegExp() method - i.e. 'add' plus the capitalised name of the nested element.
There must also be a parameter (often the same name as the nested element - e.g. RegExp).
So when Ant sees the <regexp> element, it finds the addRegExp() method, creates a an instance of the class,
then calls addRegExp() passing in that method:
matchesElement.addRegExp(new RegExp)
The same convention-based approach is used to set the attributes. This time, mapping of attributes to the AST node is by setX() methods, so the XML pattern="^21[^W]+Work.*" results in the call
regExpElement.setPattern("^21[^W]+Work.*")
Implicit AST instantiation separates the concerns - of the construction of the AST, from the definition of the class itself - so generating the AST-XML is equivalent to generating the AST. The combination of AST-XML and implicit AST instantiation removes all the syntax and grammar work that used to be required to define a language.
Summary for dummies:
- The AST is the Great Divide of Code Generation, joining the expression of intent - the language - to the processor that is going to carry out the intention.
- An AST is isomorphic to an XML document; there is a natural "AST-XML" mapping.
- Technical language developers are starting to use XML dialects as DSLs.
- AST-XML plus implicit instantiation removes all need for the language designer to implement syntax and grammar processing
AST Representation
Code generators (or interpreters) are programs and so there needs to be a generate-time representation of the AST. This is usually implemented by defining classes (in the same as the generators language - Java, C# etc.) for the concepts, fields for the properties and lists for nested children:
Class Entity extends ASTNode { // concepts become classes
String name; // additional attributes become fields
String dataSource;
ArrayList<Attribute> attributes; // children become lists
ArrayList<ASTNode> children; // alternate view of children in order
}
Class Attribute extends ASTNode {
String forename;
String lastName;
}
For small applications, it is most convenient to define these directly in Java. When you have more than 50 classes or so, it is easier to generate the classes for the generate-time representation. This not only saves coding time (you can generate about 50% of the code at this level); it is also easier to change when the structure of the generate-time classes. The definition of the classes in the AST is what the UML folk call a MetaModel and should precisely define the classes for the concepts in the DSL or model. Here are the classes above turned into a BusinessObjects meta-model, which includes the Entity amongst others:
<MetaModel name="BusinessObjects"> <ASTClass name="Entity" > <Property name="name" /> <!-- String is the default --> <Property name="dataSource" /> <List name="Attributes" type="Attribute" /> <!-- list of children automatically generated on all ASTClasses--> </ASTClass> <ASTClass name="Property" > <Property name="forename" /> </ASTClass> <MetaModel name="BusinessObjects">
In our experience, building a meta-model is made much more valuable if the user (i.e. programmer, or end-user, as appropriate) documentation is written along with the definition of the meta-model. The concepts in a domain are absolutely key to most projects' well-being, but their meaning has a habit of shifting over time; the documentation anchors the meaning to the original definition and also serves to communicate between project members.
The final point to note about AST classes/meta-models is that the meta-model (apart from that elusive meaning!) are much more stable than most other artifacts. Technologies come and go, more features get added into the code generation stage, other architectures are addressed ... but the meta-model changes very little over time.
Summary for dummies:
- A meta-model is a definition of the concepts, attributes and composition of the AST classes. It can also include validation and 3GL code for operating on the nodes.
- Meta-models define the abstract syntax rather than the concrete syntax. Given our focus on code generation, the meta-model is more useful than a grammar definition like BNF.
System Generation
You may be slightly nervous by now that, in a paper about "Code Generation", we will never get to a section about it. And you would be right!
We believe it is more correct to talk about "system generation", because these days development is just as much about specifying annotations and configuration as it is about writing code. This is no problem for modern generation systems that use the templating approach, because these can which can generate any type of output, not just code.
There are a number of levels to system generation, which appear in the following sequence.
Level 1 - Single File
Generation of a single file of code is relatively simple, using the templating idea, where we insert variables into some constant text representing the type of file generated. This level of code generation is also called Model-to-Text or M2T. In theory, you could of course write a generator in Java or C#, and this works for small applications. In practice, this approach is ugly and inconvenient, which is why specialised languages have emerged for this job.
There are more generation engines than you can count. For the Java world, Velocity is very convenient - it seems to be the choice for model-driven engines.
Different generation 'engines' have various ways of specifying the variable bits in a template text. So let's look at a Velocity template as an example:
1 class $name
2 {
3 #foreach( $property in $propertyList )
4 #if( ! $property.type )
5 #set( $property.type = "String" )
6 #end
7 $property.type $property.name;
8 #end
9 #foreach( $lst in $listList )
10 #if( ! $lst.type )
11 #set( $lst.type = $this.capitalise( $lst.name ) )
12 #end
13 ArrayList<${lst.type}> $lstName;
14 #end
15 }
There are two streams here: on the right is the template for the textual output; on the left are Velocity directives to guide the processing. Quick notes:
Line 1 $name is a reference to a field in the "context object" - which is the AST object this is template is being run for. The name picked output by introspection, so $name will take on the values name and dataSource.
Line 3 #foreach( $x in $someList ) - nested XML elements like <property> and <list> are made available through the '...List' object - i.e. propertyList and listList in this case.
By convention, nested <property> items are collected into the propertyList object.
Line 4 #if( ! $property.type ) - Velocity's if statement. The '!' means logical not, and the following expression uses existence as logical true.
Line 5 So if the property type is not defined, then this statement sets the property type to the default, which is "String".
Line 6 This is an output line and results in e.g. "String name;".
Line 13 $this.capitalise() - Velocity uses Java introspection to pick out available methods on the context object. "capitalise" is a standard library method.
The sort of generation shown here is exactly what some people mean by the term "code generation" - converting a model to a programming language like C++ or Java. The following sections describe the elaborations on single-file code generation.
Summary for dummies:
- To generate simple text files, generators use a templating approach. The template has a mix of constant and variable text; the variable portions are retrieved by evaluating an expression using values from the context object.
Level 2 - One Modelled Element, Multiple Files
One of the slogans about code generation is that it can raise your level of abstraction. Here is our example of this idea. It occurs when one modelled element (AST node) creates more than one output file; so the modelled concept (e.g. entity) is more abstract than the realization in Java or C#. Here is the generator creating a range of files required to implement the Entity concept:
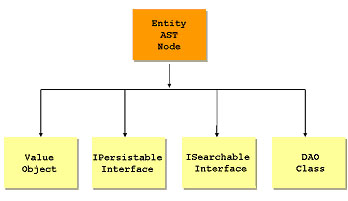
The generation system must provide ways to specify this. There must be a workflow coordinator that runs the generator multiple times on the same context object using different templates. In a Java environment, this can be done by invoking an Ant or Maven build for the component: it can run the code generator multiple times on the same object using different templates.
Ant build for Entity component - multiple invocations of file generator
Note that, if we use Ant or some other general-purpose build coordinator, then we can not only generate files, we can also compile classes, create Jars, run tests and so-on. This means that the generator is not just generating code; it's generating coordinated executables like Jars or Wars in the Java environment.
Level 3 - The Complete Tier
If we have a model for one layer of architecture, like the persistence layer, then the next step is to run a build for every object in the AST. This will generate a complete architectural tier.
The mechanics are to use a tree-walker to visit each node in the AST, bottom-up, to build smaller components first, and then assemble them into larger components. At each node, the tree-walker runs the build on the component if possible. For example, methods quite often generate 'snippets' as part of their build; class-level objects produce class files; at the next level up, the Jar can compile all the classes and collect them into a Jar; and so on to application and deployment.
In other words, using the tree-walker, it is possible to do a "manufacturing assembly" of the complete model to produce a complete tier of the target architecture.
If the tree-walking is part of the generator framework, the individual component can just "build itself", and leave it up to the framework to do the assembly.
Interlude - Reverse-Engineering and Business Logic
With time, we gradually increase the amount of a system that we can build. In 2001, getting 50% code generation was pretty good; now, 95-97% generation is possible. However, there is still hand-written code to weave into the generated framework.
First of all, let's talk about the features, then we'll discuss implementation. The most common approach in supporting business logic is to mark, in the template, an area that is to be preserved when the file is regenerated:
int myMethod( String s ) {
/********** special section begin ***********/
return 0;
/********** special section end ***********/
}
When the method is first generated, the boilerplate code "return 0" is inserted; thereafter, any changes are preserved when the method is regenerated. This looks like a fairly easy facility to implement at first sight. But what happens when the method name or signature is changed, or the method is moved to a different class? Most systems don't handle this too well, and it causes enough problems to give code generation a bad name.
The general solution hinges on marking every model element with a unique ID in some way - which is fine because all modelling tools seem to do this now, although it does give problems if other approaches are used. Then the markers can incorporate the UID:
int myMethod( String s ) {
/********** UID: 1234-5678-90AB begin ***********/
return 0;
/********** UID: 1234-5678-90AB end ***********/
}
To handle moving methods between files, all the special sections for all the generated code must be extracted before generation begins and then re-inserted as part of the generation - possibly into another file if the method has moved. Also, to handle renaming of classes, the generator must keep track of files as it generates them and remove any files that are no longer required by the build. Files normally become obsolete because the model changes, but it can also be because a change in naming standards has been implemented.
One of the advantages of code generation is that you can very easily generate complete trace information - all methods entries and exits, plus logging parameters and return values - for a method (we tend to do this during debugging, then remove it on going to system test to get the best performance). This is invaluable in distributed programming for example.
As an interesting side-note, our experience is that it is much easier to implement this type of work using text searching than parsing the language files. Given the right text-handing tools, it only takes a handful of statements to parse generated files and pick out the special code.
A final point, to do with encouraging programmers to keep their hands off the generated code. First, you can collect all the infrastructure into a Base class and have the user-viewed class inherit off that; this reduces the temptation for the programmer to start changing generated properties. This seems to be a well-accepted approach. Another clue is to separate the generated-only source and put it into a different directory tree from the implementation classes.
Level 4 - Language Techniques
Writing templates for individual files on a given generation target can take you so far - up to around 50 or 100 templates, the refactoring and maintenance load is tractable. To build more complicated architectures, different techniques are needed; we now address the specific language features for handling code generation.
We have already seen a very important - if mundane - technique for writing templates, namely indentation. This becomes vitally important as the generation logic and the output itself get more complex. Generating JSPs for web pages is the worst: it is easily possible to have 5 levels of nesting in the Velocity script and 15 in the output. Without indentation, this becomes impossible.
One of the big issues in generation is the support from the underlying language of the AST. For example, if the AST classes are implemented in Java, can you get support from Java? Velocity provides features to evaluate expressions and set properties on the underlying Java objects. As Velocity is open source, it is easy to extend it to create additional objects - i.e. objects that weren't created as part of the AST - to hold snippets of text, lists (e.g. $newArrayList to create an ArrayList object) and so on. This general approach - to give unrestricted access to the features of the AST language - avoids the need to recreate Java functionality in Velocity and makes the approach more acceptable to developers used to Java.
.. and so what is the split in responsibility between the M2T language and Java? The simple answer is that, once the generation system grows past a few hundred templates, you'll take all the help you can get!
The OMG has a language in this category called MOF2Text, the 'MOF' part of that being UML model elements (". This is not widely accepted to our knowledge and this must surely be in part to its basis on "MOF" objects, which - like the more exotic products of atomic collisions - are not often seen in the wild. The MOF2Text 'library' contains around 20 methods; the Java library contains thousands of classes and over 10,000 methods. The ability to leverage a well-known and popular language compared to using a small and immature language for the underlying objects makes it clear why the Velocity approach is more powerful.
There are further issues that arise in generating large systems which we do not have space to discuss here. In summary, these tend to focus the language and its utility methods on the domain of generation, which is basically text handling and AST walking.
Level 5 - Model-to-Model (M2M)
The main technique to handle large-scale architecture, and also abstractions, is a Model-to-Model (or M2M) approach. The original motivation for this, as expressed in the OMG's MDA approach, was to create a series of "platform-independent models" (PIMs), each of levels decreasing abstraction, until finally the "platform-specific model" (PSM) was reached, and which point Model-to-Text could be used.
Our experience, from building generation systems comprising thousands of templates, is that this theory is not borne out in practice:
- the "series of PIMs" does not occur in practice
- we have never generated a purely abstract intermediate object (in an intermediate PIM)
- model-to-model transforms only make sense when they enhance the AST rather than creating new models - this is better done by writing XML and reading that in.
- the "platform-specific model" is better handled by a workflow component that generates multiple output files for one object - see the "Level 2" section above - so there is really no need for a separate PSM.
However, we do find practical applications of the M2M approach to enhance the AST (i.e. the input model) in these situations:
- generate smart defaults. For example, in a persistence application, generate primary keys and onLoad/onStore methods if they have not been specified in the model;
- generate Java using a (platform-specific) model of Java (i.e. generate "<class.../>" output rather than "class { }"). This allows different flavours of class{} to be generated and reduces the effort to maintain the mapping to Java.
- to create new tiers and other architectural patterns, described next.
When we build architectural tiers, we need to project one tier into another. For example, in creating CRUD pages, we want to "project" the data tier into pages - typically one user-facing page per entity. The same occurs with normal Java patterns such as the facade pattern or master-worker patterns. This overall approach is recursive: it can be repeated throughout the tiers. For example, to build an end-to-end CRUD pattern, we do this:
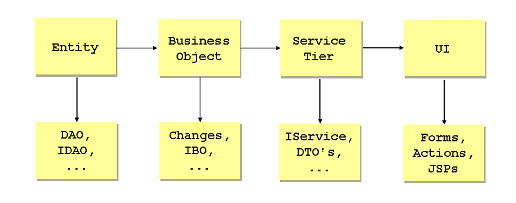
The entity generates its own implementation objects ( DAO etc.) as described previously. It also generates a related business object, that is a simple projection of the persistence tier object to the business object layer. This object sits in the mid-tier and has the main business logic and data transformations from the service interface requirements back to the database.
The pattern is repeated in the business object: it creates objects for its own implementation, then projects itself into the service tier by generating an object for doing CRUD operations on the business object - with create, read, update and delete operations on it! And so on.
There are a number of languages around to do this - QVT and ATL for example. Given our view of special purpose languages, we feel a much better approach is to use XML. Here is an example of a model-to-model generation, simply writing the class-generation example above as a model-to-model transform to create the data transfer object.
1 <class name="$name" >
3 #foreach( $property in $propertyList )
4 #if( ! $property.type )
5 #set( $property.type = "String" )
6 #end
7 <field name="$property.name"
type="$property.type"
/>
8 #end
15 </class>
This approach is very powerful because
- it separates the AST-XML generation from the reading in to the AST (which will be the same as the original AST read-in) in an XML and subsequent model-to-text generation. All these concerns are separated into independently-maintained parts
- it is recursive - a model element can project itself through multiple tiers, just as is required by the CRUD pattern. In an enterprise architecture, cross-tier patterns like this expand the number of model elements in the build by a factor of 20 (for a lightweight stack like Hibernate, Spring, JSF and Apache Trinidad) and 50 times (for J2EE).
Level 6 - System Generator Product Lines
There are additional code generation techniques that become important when building a range of product generators - like aspects, using symbolic names via the AST, overridable objects for generating the small details in a number of technical areas, swapping technologies around, and allowing for customer enhancements that easily change the core of the generation.
These are not general techniques in use today, so we will leave them for another time - you will be happy to hear.
Conclusion
We have talked a great deal about the techniques of Domain- and General-Purpose Languages, Modelling and Code Generation. Using these techniques as a platform, how does our view of software development change?
When my company first started doing system generation, the largest cost was the simple mechanics of writing lots of transforms. With better techniques, this cost has reduced significantly, so the largest cost now is understanding the platforms we are targetting. In other words, we find that most of what we do is get the know-how for the platform, understand the patterns of best practice and provide sample architectures. Writing the transforms for all of this is relatively straightforward.
However, we also note that most of the concepts remained unchanged - some of the definition files haven't changed in 5 years. This means that models we created back then will still work today.
Development groups of all sorts have exactly the same issues of learning new areas and migrating. So whereas we used to see automation and quality as the biggest benefits of code generation, now the main benefits are in reducing the amount of learning and the risk of creating a bad architecture and - when the time comes - the cost of migrating.
The significance of the interest in DSLs is that there will not be a universal successor to 3GLs of today. So the best hope for advancement in delivering business value effectively is the use of modelling and DSLs - be they technical or user-oriented - integrated with 3GL code, and projected forward into model-driven testing and deployment. For implementing models and DSLs, and integrating them with 3GLs, there will be a growing role for code generation.
References
ANTLR http://www.antlr.org/
ATL http://www.eclipse.org/m2m/atl/doc/
awk http://www.gnu.org/software/gawk/manual/gawk.html
BNF Backus Naur Form versus Backus Normal Form
http://compilers.iecc.com/comparch/article/93-07-017
Code Generation http://en.wikipedia.org/wiki/Source_code_generation
grep http://www.opengroup.org/onlinepubs/007908799/xcu/grep.html
Lex http://dinosaur.compilertools.net/lex/
MDA http://www.omg.org/docs/omg/03-06-01.pdf
Programming Languages Peter Wegner "Programming Languages - The First 25 Years"
http://www.cs.ucdavis.edu/~su/teaching/ecs240-08/readings/PLHistoryDesign25yrs.PDF
QVT http://www.omg.org/docs/formal/08-04-03.pdf
Regular expressions http://www.opengroup.org/onlinepubs/007908799/xbd/re.html
sed http://www.opengroup.org/onlinepubs/007908799/xcu/sed.html
YACC http://dinosaur.compilertools.net/yacc/
Click here to view the complete list of archived articles
This article was originally published in the Spring 2009 issue of Methods & Tools
|
Methods & Tools Software Testing Magazine The Scrum Expert |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


