|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
An Introduction to Domain Driven Design - Page 2
Dan Haywood, Haywood Associates Ltd, http://danhaywood.com/
Building Blocks
As we've already noted, most DDD systems will likely use an OO paradigm. As such many of the building blocks for our domain objects may well be familiar, such as entities, value objects and modules. For example, if you are a Java programmer then it's safe enough to think of a DDD entity as basically the same thing as a JPA entity (annotated with @Entity); value objects are things like strings, numbers and dates; and a module is a package.
However, DDD tends to place rather more emphasis on value objects than you might be used to. So, yes, you can use a String to hold the value of a Customer's givenName property, for example, and that would probably be reasonable. But what about an amount of money, for example the price of a Product? We could use an int or a double, but (even ignoring possible rounding errors) what would 1 or 1.0 mean? $1? €1? ¥1? 1 cent, even? Instead, we should introduce a Money value type, which encapsulates the Currency and any rounding rules (which will be specific to the Currency).
Moreover, value objects should be immutable, and should provide a set of side-effect free functions to manipulate them. We should be able to write:
Money m1 = new Money("GBP", 10);
Money m2 = new Money("GBP", 20);
Money m3 = m1.add(m2);
Adding m2 to m1 does not alter m1, instead it returns a new Money object (referenced by m3) which represents the two amounts of Money added together.
Values should also have value semantics, which means (in Java and C# for example) that they implement equals() and hashCode(). They are also often serializable, either into a bytestream or perhaps to and from a String format. This is useful when we need to persist them.
Another case where value objects are common is as identifiers. So a (US) SocialSecurityNumber would be a good example, as would a RegistrationNumber for a Vehicle. So would a URL. Because we have overridden equals() and hashCode(), all of these could then safely be used as keys in a hash map.
Introducing value objects not only expands our ubiquitous language, it also means we can push behaviour onto the values themselves. So if we decided that Money can never contain negative values, we can implement this check right inside Money, rather than everywhere that a Money is used. If a SocialSecurityNumber had a checksum digit (which is the case in some countries) then the verification of that checksum could be in the value object. And we could ask a URL to validate its format, return its scheme (for example http), or perhaps determine a resource location relative to some other URL.
Our other two building blocks probably need less explanation. Entities are typically persisted, typically mutable and (as such) tend to have a lifetime of state changes. In many architectures an entity will be persisted as row in a database table. Modules (packages or namespaces) meanwhile are key to ensuring that the domain model remains decoupled, and does not descend into one big ball of mud [6]. In his book Evans talks about conceptual contours, an elegant phrase to describe how to separate out the main areas of concern of the domain. Modules are the main way in which this separation is realized, along with interfaces to ensure that module dependencies are strictly acyclic. We use techniques such as Uncle "Bob" Martin's dependency inversion principle [7] to ensure that the dependencies are strictly one-way.
Entities, values and modules are the core building blocks, but DDD also has some further building blocks that will be less familiar. Let's look at these now.
Aggregates and Aggregate Roots
If you are versed in UML then you'll remember that it allows us to model an association between two objects either as a simple association, as an aggregation, or using composition. An aggregate root (sometimes abbreviated to AR) is an entity that composes other entities (as well as its own values) by composition. That is, aggregated entities are referenced only by the root (perhaps transitively), and may not be (permanently) referenced by any objects outside the aggregate. Put another way, if an entity has a reference to another entity, then the referenced entity must either be within the same aggregate, or be the root of some other aggregate.
Many entities are aggregate roots and contain no other entities. This is especially true for entities that are immutable (equivalent to reference or static data in a database). Examples might include Country, VehicleModel, TaxRate, Category, BookTitle and so on.
However, more complex mutable (transactional) entities do benefit when modelled as aggregates, primarily by reducing the conceptual overhead. Rather than having to think about every entity we can think only of the aggregate roots; aggregated entities are merely the "inner workings" of the aggregate. They also simplify the interactions between entities; we follow the rule that (persisted) references may only be to an aggregate's root, not to any other entities within the aggregate.
Another DDD principle is that an aggregate root is responsible for ensuring that the aggregated entities are always in a valid state. For example, an Order (root) might contain a collection of OrderItems (aggregated). There could be a rule that any OrderItem cannot be updated once the Order has been shipped. Or, if two OrderItems refer to the same Product and with the same shipping requirements, then they are merged into the same OrderItem. Or, an Order's derived totalPrice attribute should be the sum of the prices of the OrderItems. Maintaining these invariants is the responsibility of the root.
However ... it is only feasible for an aggregate root to maintain invariants between objects entirely within the aggregate. The Product referenced by an OrderItem would almost certainly not be in the AR, because there are other use cases which need to interact with Product independently of whether there is an Order for it. So, if there were a rule that an Order cannot be placed against a discontinued Product, then the Order would need to deal with this somehow. In practical terms this generally means using isolation level 2 or 3 to "lock" the Product while the Order is updated transactionally. Alternatively, an out-of-band process can be used to reconcile any breakage of cross-aggregate invariants.
Stepping back a little before we move on, we can see that we have a spectrum of granularity:
value < entity < aggregate < module < bounded context
Let's now carry on looking at some further DDD building blocks.
Repositories, Factories and Services
In enterprise applications entities are typically persisted, with values representing the state of those entities. But how do we get hold of an entity from the persistence store in the first place?
A repository is an abstraction over the persistence store, returning entities - or more precisely aggregate roots - meeting some criteria. For example, a customer repository would return Customer aggregate root entities, and an order repository would return Orders (along with their OrderItems). Typically there is one repository per aggregate root.
Because we generally want to support multiple implementations of the persistence store, a repository typically consists of an interface (eg CustomerRepository) with different implementations for the different persistence store implementations (eg CustomerRepositoryHibernate, or CustomerRepositoryInMemory). Because this interface returns entities (part of the domain layer), the interface itself is also part of the domain layer. The implementations of the interface (coupled as they are to some specific persistence implementation) are part of the infrastructure layer.
Often the criteria we are searching for is implicit in the method name called. So CustomerRepository might provide a findByLastName(String) method to return Customer entities with the specified last name. Or we could have an OrderRepository to return Orders, with a findByOrderNum(OrderNum) returning the Order matching the OrderNum (note the use of a value type here, by the way!).
More elaborate designs wrap the criteria into a query or a specification, something like findBy(Query<T>), where Query holds an abstract syntax tree describing the criteria. The different implementations then unwrap the Query to determine how to locate the entities meeting the criteria in their own specific way.
That said, if you are a .NET developer then one technology that warrants mention here is LINQ [8]. Because LINQ is itself pluggable, it is often the case that we can write a single implementation of the repository using LINQ. What then varies is not the repository implementation but the way in which we configure LINQ to obtain its data sources (eg against Entity Framework or against an in-memory objectstore).
A variation on using specific repository interfaces per aggregate root is to use generic repositories, such as Repository<Customer>. This provides a common set of methods, such as findById(int) for every entity. This works well when using Query<T> (eg Query<Customer>) objects to specify the criteria. For the Java platform there are also frameworks such as Hades [9] that allow a mix-and-match approach (start with generic implementations, and then add in custom interfaces as and when are needed).
Repositories aren't the only way to bring in objects from the persistence layer. If using an object-relational mapping (ORM) tool such as Hibernate we can navigate references between entities, allowing us to transparently walk the graph. As a rule of thumb references to the aggregate roots of other entities should be lazy loaded, while aggregated entities within an aggregate should be eagerly loaded. But as ever with ORMs, expect to do some tuning in order to obtain suitable performance characteristics for your most critical use cases.
In most designs repositories are also used to save new instances, and to update or delete existing instances. If the underlying persistence technology supports it then these may well live on a generic repository, though ... from a method signature point of view there's nothing really to distinguish saving a new Customer from saving a new Order.
One final point on this... it's quite rare to create new aggregate roots directly. Instead they tend to be created by other aggregate roots. An Order is a good example: it would probably be created by invoking an action by the Customer.
Which neatly brings us onto:
Factories
If we ask an Order to create an OrderItem, then (because after all the OrderItem is part of its aggregate) it's reasonable for the Order to know the concrete class of OrderItem to instantiate. In fact, it's reasonable for an entity to know the concrete class of any entity within the same module (namespace or package) that it needs to instantiate.
Suppose though that the Customer creates an Order, using the Customer's placeOrder action (see Figure 6). If the Customer knows the concrete class of Order, that means that the customer module is dependent on the order module. If the Order has a back-reference to the Customer then we will get a cyclic dependency between the two modules.
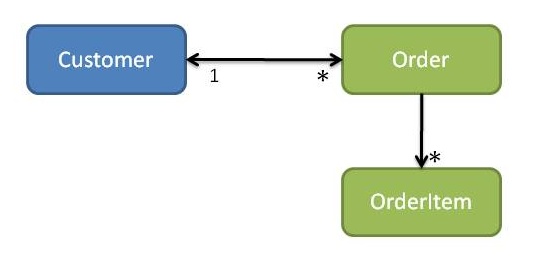
Figure 6: Customers and Orders (cyclic dependencies)
As already mentioned, we can use the dependency inversion principle to resolve this sort of thing: to remove the dependency from order -> customer module we would introduce an OrderOwner interface, make Order reference an OrderOwner, and make Customer implement OrderOwner (see Figure 7).
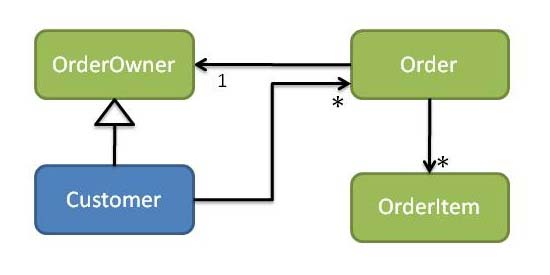
Figure 7: Customers and Orders (customer depends on order)
What about the other way, though: if we wanted order -> customer? In this case there would need to be an interface representing Order in the customer module (this being the return type of Customer's placeOrder action). The order module would then provide implementations of Order. Since customer cannot depend on order, it instead must define an OrderFactory interface. The order module then provides an implementation of OrderFactory in turn (see Figure 8).
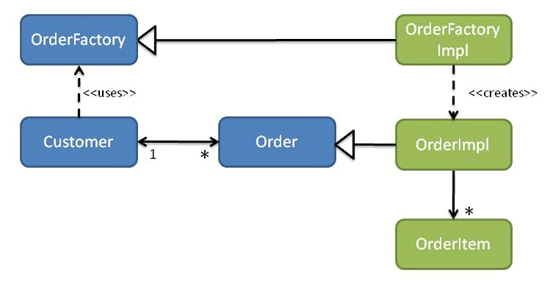
Figure 8: Customers and Orders (order depends on customer)
There might also be a corresponding repository interface. For example, if a Customer could have many thousands of Orders then we might remove its orders collection. Instead the Customer would use an OrderRepository to locate (a subset of) its Orders as required. Alternatively (as some prefer) you can avoid the explicit dependency from an entity to a repository by moving the call to the repository into a higher layer of the application architecture, such as a domain service or perhaps an application service.
Indeed, services are the next topic we need to explore.
Domain services, Infrastructure services and Application services
A domain service is one which is defined within the domain layer, though the implementation may be part of the infrastructure layer. A repository is a domain service whose implementation is indeed in the infrastructure layer, while a factory is also a domain service whose implementation is generally within the domain layer. In particular both repositories and factories are defined within the appropriate module: CustomerRepository is in the customer module, and so on.
More generally though a domain service is any business logic that does not easily live within an entity. Evans suggests a transfer service between two bank accounts, though I'm not sure that's the best example (I would model a Transfer itself as an entity). But another variety of domain service is one that acts as a proxy to some other bounded context. For example, we might want to integrate with a General Ledger system that exposes an open host service. We can define a service that exposes the functionality that we need, so that our application can post entries to the general ledger. These services sometimes define their own entities which may be persisted; these entities in effect shadow the salient information held remotely in the other BC.
We can also get services that are more technical in nature, for example sending out an email or SMS text message, or converting a Correspondence entity into a PDF, or stamping the generated PDF with a barcode. Again the interface is defined in the domain layer, but the implementation is very definitely in the infrastructure layer. Because the interface for these very technical services is often defined in terms of simple value types (not entities), I tend to use the term infrastructure service rather than domain service. But you could think of them if you want as a bridge over to an "email" BC or an "SMS" BC if you wanted to.
While a domain service can both call or be called by a domain entity, an application service sits above the domain layer so cannot be called by entities within the domain layer, only the other way around. Put another way, the application layer (of our layered architecture) can be thought of as a set of (stateless) application services.
As already discussed, application services usually handle cross-cutting concerns such as transactions and security. They may also mediate with the presentation layer, by: unmarshalling the inbound request; using a domain service (repository or factory) to obtain a reference to the aggregate root being interacted with; invoking the appropriate operation on that aggregate root; and marshalling the results back to the presentation layer.
I should also point out that in some architectures application services call infrastructure services. So, rather than an entity call a PdfGenerationService to convert itself to a PDF, the application service may call the PdfGenerationService directly, passing information that it has extracted from the entity. This isn't my particular preference, but it is a common design. I'll talk about this more shortly.
Okay, that completes our overview of the main DDD patterns. There's plenty more in Evans 500+page book - and it's well worth the read - but what I'd like to do next is highlight some areas where people seem to struggle to apply DDD.
|
Methods & Tools Software Testing Magazine The Scrum Expert |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


