|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Refactoring Large Software Systems
Sibylle Peter, Sven Ehrke, Canoo Engineering AG
Refactoring a software system means to refurbish it internally without interfering with its external properties. In his famous book Martin Fowler defines refactoring as follows:
Refactoring is the process of changing a software system in such a way that it does not alter the external behavior of the code yet improves its internal structure. [Fowl, p. xvi]
Fowler describes how to refactor code in a controlled and efficient manner. Although we frequently use these techniques to refactor large software systems, this article is not about refactoring techniques. It rather treats large scale refactoring of systems that suffer from being stuck in an infeasibility stage, which means that it is no longer possible to implement new features and that every bug fix leads to several new bugs.
In this article we describe the different stages of a refactoring project. Before a refactoring project is actually started, an assessment and an in-depth analysis are made which result in a list of findings. Ideally, these findings will be translated into a master plan, which defines WHAT should be refactored. This master plan helps to keep the overall picture of the refactoring project in mind and to divide it into several sub-projects or refactoring parts. Once the master plan is defined we use an iterative approach to tackle the individual refactoring steps. Before describing this approach we will first have a look at the life path of applications in general, followed by the prerequisites for refactoring projects.
WebInvest, our current refactoring project, will be used as example throughout the article. WebInvest is an advisory tool for investment relationship managers. It enables them to simulate trading and to analyze a customer's portfolio against investment strategies.
Application Life Path
The life path of a successful application can be divided into five different stages: Development, Introductory, Growth, Maturity and Infeasibility stage. Each stage is characterized by a specific behavior of three key indicators: productivity (number of implemented features), quality (number of bugs) and fluctuation (employee turnover). Figure 1 shows that these indicators are not independent of each other but that they can be summed up as costs per feature.

Figure 1: The life path of a long-living system
In the growth stage and in the beginning of the maturity stage the total performance is best. The overall situation is still quite stable, a lot of new features are implemented and the number of bugs is still controllable. Without any special activities regarding overall code quality, however, the situation starts to change; the application deteriorates until the infeasibility stage is reached.
The characteristics of a deteriorated system are:
- No new features can be implemented
- Every bug fix entails new bugs
- The original architecture is heavily compromised by fluctuation, e.g. new architects introduce new concepts without adjusting the overall concept, or the knowledge of the original architecture simply gets lost. This leads to a strong coupling between modules and to violations of the original layering. The principle of separation of concerns is violated which leads to unpredictable side effects.
- Many code smells like duplicated code, long methods etc. The "code smells" metaphor was introduced by Martin Fowler [Fowl]
- Insufficient test coverage prevents developers from making bigger changes in the system because they cannot guarantee the original behavior of the application.
As a consequence, it becomes nearly impossible to implement new features with reasonable effort, the side effects are no longer manageable and, eventually, the project stalls completely. For a business-critical application this is not tolerable. If it is not possible to implement new features at reasonable costs, the application loses its strategic position.
What can be done to remedy this situation? The following options can be considered:
- Application redesign: a complete redesign and new implementation of the application with all the implications of a new project (requirements engineering, GUI design, etc.) For a large application, new critical features will at the earliest be available after the first release.
- Reimplementation: in contrast to a redesign, the behavior of the application is not subject to change. The only goal is to lead the application out of the infeasibility stage. There are two different approaches for a reimplementation:
- Rewrite: This is a big bang approach, which fails most of the times, as Chad Fowler [ChFowl] describes in his article.
- Large scale refactoring: this approach allows parallel implementation of new features by ensuring that the system is always in an executable state during the refactoring.
WebInvest, our current refactoring project, had reached the infeasibility stage. After the initial assessment, the customer opted for a large scale refactoring exactly because they had several important features they wanted to realize as soon as possible. Accordingly, an application redesign and a complete rewrite could quickly be discarded.
WebInvest went productive in 2004 and was extremely successful. It still is a business-critical application for the investment banking where new time-critical features need to be implemented.
WebInvest consists of approximately 1800 java classes and 320 java server pages (JSPs). All parts of the application (EJBs and web application) are included in one overall project. Originally there was a separation between backend access layer and presentation layer, but over time this layering has become blurred. As a result, there are many dependencies between the layers as well as between the classes inside the layers (Figure 2). The business logic is scattered all over, even in the JSPs. Documentation is scarce and most of it is not up to date. None of the original developers is still available. Fortunately, the behavior of the application is well known to the testers and the business analysts.
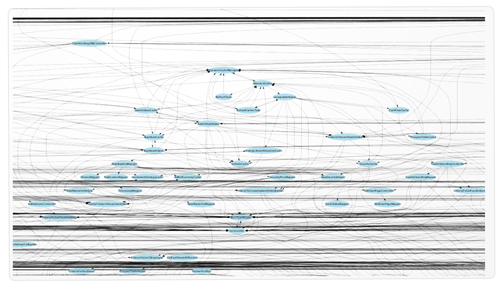
Figure 2: Extract of Class Dependencies of WebInvest
After several years of continuing modifications WebInvest moved into the infeasibility stage. The costs per feature exploded. With every bug fix several new bugs were introduced. It was almost impossible to implement minor change requests, not to speak of highly requested features.
Prerequisites for successful Refactoring Projects
Like every project, a successful refactoring project needs some prerequisites to be fulfilled. Without claiming completeness we list some of the prerequisites that are important to us. The order of priority among them depends mainly on the character of a specific project.
Team
Like in every software project, people are the most important element, and this for several reasons:
- Team size: For the refactoring of large projects it is important that the number of developers is sufficient. It is not realistic to expect that one or two persons can manage to refactor major parts of a large system and, in addition, to maintain the achieved improvements (e.g. review the ongoing changes made by the developer team). We experienced this in WebInvest when we had to reduce the refactoring team from five to two persons because of a budget cut. Fortunately it didn't last too long before we could increase the number of developers again.
- Experience: All stakeholders need to be aware that large scale refactoring projects cannot be staffed with juniors. Strong know-how in design and architecture is required. For the customer this has an impact on the budget. In large enterprises, IT people are normally fully aware of that but they may have to deal with some strange constraints from supply management.
- Motivation: Working on a dedicated refactoring project differs in many ways from working on other projects. One major difference is the character of the work: instead of expressing oneself by developing cool new features one has to read (and understand) other people's code. This is not a developer's favorite task. Applying refactorings is demanding, but it gives the satisfaction of having better code as a result.
- Lead Engineer: Even if the refactoring team consists of seniors, it is necessary to appoint a senior developer (lead engineer or architect) who a) knows the system very well and b) has the authority to approve architectural and design decisions. Good collaboration between this senior developer/architect and the refactoring team is essential. In WebInvest, the lead engineer had this function. Not only did he know the system very well but he was also aware of all the implications our decisions had on the surrounding systems and infrastructure. He also applied the new architecture on the first new feature, which was developed in parallel. The feedback we got from this was extremely helpful for the new design.
Position and Management Support
Even if the customer agrees that a large refactoring is needed for a project/application, the situation for the refactoring team can be difficult. If they are not part of the developer team, it is important to avoid wasting time with politics. It is crucial that the refactoring team has the authority and the position to make important design/architectural decisions and that it is involved in the design process. Trust and support from the line and project management facilitates this. However, the refactoring team should not only establish a good relationship with the management, but also with the whole team, including business and testers.
Flexibility
Large refactoring projects are no short-term projects. Like in every large project, there will always be changes to the original plan. To work efficiently, it is important that both the refactoring team and the customer show some flexibility. Making adjustments to the original plan is a lot easier if there is mutual trust between the developer team and the refactoring team. Planning changes is a lot easier in an agile environment. In more traditional environments, it is advisable to plan a refactoring in small steps. We concentrated on refactoring tasks in areas where new features were implemented. This early involvement in the ongoing development allowed us to incorporate future requirements into the architecture. This prevented newly implemented features to become refactoring tasks right after their implementation.
Continuous Integration
In our opinion, continuous integration is an absolute must. If no (working) build server is available, make it work first or install a new one. The developer team of WebInvest had a continuous integration server and a staging server. The build server has been maintained by another team, which made any change request (such as setting up continuous integration on a branch) very time-consuming. The tests were not run on the continuous integration server, partly because they were never fixed when they did not run and partly because of infrastructural problems. To avoid long response times, we decided to set up TeamCity [TEAM] on a spare developer machine and to use our own build server infrastructure. TeamCity can easily be maintained remotely via a web interface. Avoiding the official build server, we could also run the integration tests at night and were thus able to detect bugs much faster.
Automated Tests
Automated tests are the lifeline for a refactoring project because they ensure that the behavior of the application does not alter. However, there are situations in which the test coverage is not high enough. If there is a way to increase the test coverage before starting, it should definitely be implemented. For most of our refactoring projects, integration tests proved to be far more valuable than unit tests. Unless unit tests tackle isolated application logic (which wasn't the case in WebInvest, for example) they need to be maintained during the refactoring. In a deteriorated system, existing unit tests or new unit tests that cover old code do not support refactoring because they stabilize old code structures. High coupling between classes means that maintaining these unit tests is very laborious and their cost-benefit ratio is too high.
That is why integration tests are much better suited for large scale refactoring projects. In WebInvest, automated integration tests (realized as Canoo Webtests [CWT]) covered about 50% of the code. They had been badly maintained and failed to run successfully when we started. Since they were our life-line we decided to fix them first. We pointed out to the customer that end-to-end tests against the GUI are sufficient for the first two parts of the master plan, but that they cannot be used any more when the GUI changes. Since they cover a lot of business logic, they must be divided into integration tests without GUI involvement and simple GUI tests. We started to write GUI independent integration tests for the refactored part. However, the project still relied heavily on manual testing. Manual testing worked for the development team because changes had only been made in well-defined areas. Refactoring requires full regression tests and, currently, a manual complete regression test takes three person-weeks to perform. That is why these tests were executed only before a quarterly release.
Stubbing
It can be helpful to reduce dependencies on other systems like backend services, databases etc. Stubbing allows continuing development even if the surrounding systems are unstable or unavailable. WebInvest relied heavily on other systems, databases, host services and other applications. Host services in particular have not been very reliable. We therefore suggested to support the refactoring by stubs and implemented the necessary infrastructure on top of the new service layer.
Stubbing not only improves the development process, but it also provides stable test data that help automated tests to run more reliably.
Assessment and Master Plan
An assessment is likely to be performed if costs per feature are getting out of control. The goal of the assessment is to investigate the reasons for the deteriorated state of the application. It defines which areas are worth to be kept and which areas should be replaced. On the basis of the result of the assessment, the management decides how to proceed with the application. If a large scale refactoring is chosen, the findings define the scope of the refactoring and help to draw up the master plan. The master plan should focus on refactoring of areas the system benefits most of. Of course there will always be changes, but the goal of the master plan is to keep the big picture in mind.
In the assessment of WebInvest the following major findings were identified:
- Many dependencies between layers and objects
- No separation of concerns
- No use of standard frameworks, especially in the presentation layer
- Much unnecessary caching
- Many side effects
As a result of the assessment a refactoring project was set up as well as the following master plan consisting of three parts (see also Figure 3):
- A clear separation between the service layer and the presentation layer . The primary goal was to implement a service oriented approach (SOA) with a clear design in the service layer. Especially the different kinds of backend services (host, database and web services) were to be encapsulated. The success of this step was measured by the number of architectural offenses, which means that all dependencies between the service layer and the presentation layer had to be removed.
- Clean up the presentation layer . The goal was to move all remaining business logic from the presentation layer to the service layer. Business logic was distributed all over the application and only after the presentation layer would have been stripped it would be possible to replace the GUI technology with a standard framework.
- Replace the homegrown GUI framework with standard technology . In the original plan it was not clear if only the technology was to be replaced and the GUI was to remain as it was. Now it seems that rich GUI technology is to be used, which, of course, would result in a redesign of the GUI.
For each part a rough estimation of about five person-years was budgeted. Currently we are in the middle of the second part while preparations for the third part have already started (GUI analysis and framework evaluation).
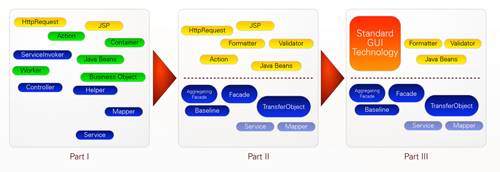
Figure 3: Visualization of WebInvest Masterplan
Figure 4 shows the refactoring approach we applied on the individual parts of the master plan. For every refactoring task we follow three steps:
- Analysis: definition of the desired result and HOW to achieve it.
- Implementation: application of refactoring techniques to alter the code accordingly.
- Stabilization: application of methods, which ensure that the result of the implementation is durable.
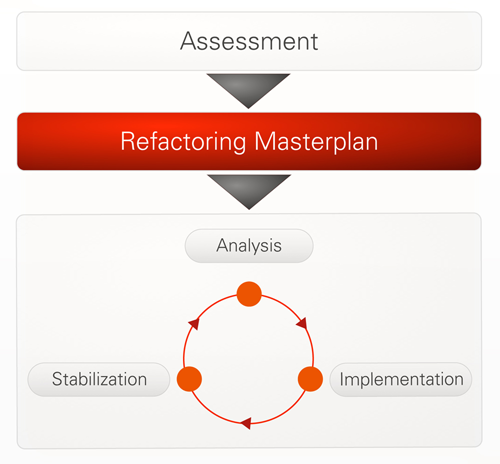
Figure 4: Iterative Refactoring Approach
Analysis
When we tackle a new refactoring story, we always start with an in-depth analysis. We try to choose neither the simplest nor the most complicated case for the analysis. One goal of this analysis is to verify the new architectural and design concepts. Another equally important goal is to define the HOW, i.e. to find the best way to achieve the new design without taking too many risks. This includes to discover the order of the steps in which an actual refactoring can be made without breaking to much code at one time. The Mikado Method describes such an approach, see What is the Mikado Method? As we mentioned earlier, the test coverage is not always high enough to allow us to rely entirely on tests.
If the system is as entangled as WebInvest, individual refactoring tasks cannot be accomplished without temporarily introducing more complexity into the system, e.g. introducing adapter layers. This additional complexity is needed to bridge the gap between the new design and the original system because it is simply not feasible to introduce a new design into a large complex system in one single step. Refactoring means that the system must be running continuously to enable simultaneous implementation of enhancements and new features.
In WebInvest, the first part of the master plan was to introduce a clear separation between service layer and presentation layer. The primary goal was to remove dependencies between these two layers. When analyzing the remains of the original service layer we discovered that a bottom-up approach would work best. By taking the backend services as starting point we implemented the new design of the service layer and removed side effects and architectural violations.
The separation of the layers was achieved by the facade pattern [Facade]. The facade serves as the interface to the service layer and thus hides the actual implementation of the service layer from the presentation layer. To further prevent undesired side effects, we decided to work with immutable transfer objects, which together with the facade implementation belong to the public API (Application Programming Interface) of the service layer. Because the presentation layer relies deeply on the entangled business object model, we had to introduce an adapter layer (see Figure 5). The adapter layer consists of so-called converter classes which build the business object model from the immutable transfer objects and vice versa. This approach allowed us to clean up the service layer without having to change the GUI implementation. This was an additional benefit because the GUI implementation is going to be replaced with a standard framework anyway, so that any refactoring work on it would have been wasted.
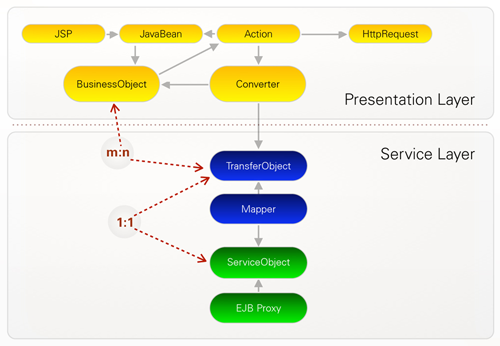
Figure 5: Adapter (Converter) between refactored service layer and old presentation layer
During the analysis we gained a common understanding of the new architecture and established best practices for how to realize these changes. Therefore, the refactoring of the 40 facades could be distributed among several developers.
Implementation
After a common understanding of the design has been established, the code parts must be moved to their appropriate place according to the principle of separation of concerns. Usually this means moving them to the appropriate layer and module inside that layer. Depending on the application's state, this can be very laborious. Each class must be analyzed to discover it's main purpose before it can be moved. Cleaning up the code (e.g. removing all unused code, introducing type safety) helps a lot to understand what actually is happening.
With classes that serve one clear purpose this is relatively easy. If a class fulfills more than one purpose, it must be split up before moving the separate parts. That can be quite tricky. In WebInvest we decided to split up classes only in those cases in which it was necessary to isolate parts of the system in order to allow simultaneous refactoring. Here, we introduced more complexity into the system, like - as described earlier - when we introduced the adapter layer between the service and presentation layer.
Business logic that was supposed to be in the service layer but was too complex to be refactored at that time was marked and left where it was. According to the master plan, we concentrated on the separation of the layers. The business logic will be removed from the presentation layer in the second part of the master plan. Sticking to the plan proved to be essential to get the first part finished. When refactoring deteriorated code, one easily gets lost because there is so much to do.
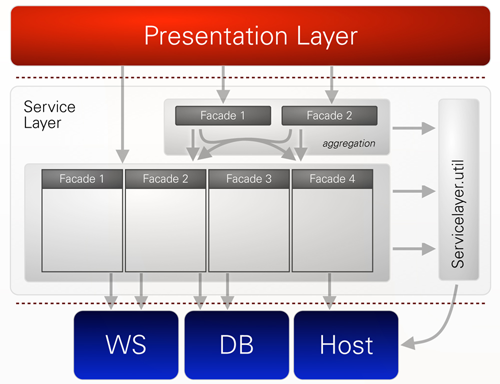
Figure 6: Service Layer Architecture of WebInvest
The service layer was divided into packages representing a specific business domain with a facade as the API to the presentation layer (see Figure 6). Each developer of the refactoring team worked on a couple of facades. We established the following criteria for the completion of this refactoring step:
- Transfer objects are immutable. WebInvest suffered greatly from side effects like getters that also modified objects. Such code is hard to read and makes analysis and refactoring very difficult, especially when it is used deep in the call stack. One of the advantages of immutable objects is the easy implementation of class invariants and validity checks (see [Bloch] and [DbC] for more information about the advantages of immutable objects).
- Base types that encapsulate strings are to be used where available. With the use of base types, the API of the facades as well as the code throughout the service layer become much easier to read, because one does not have to guess what kind of parameter is needed. It also prevents oversights, as it is easy to switch parameters of the same type. That is not possible with base types.
- Each facade is self-contained, i.e. there are no references to other facades.
- Naming conventions have been adhered to.
In addition to these criteria we reviewed each other's code to achieve consistency throughout the refactored code.
Stabilization
As said in the very beginning, refactoring code is not enough. Actions are needed to maintain the achieved quality of the code. As shown in Figure 4, after every release of refactored code, stabilization actions must be carried out:
- Explain the new concepts behind the refactored code
- Introduce new guidelines how to work with the refactored code
- Introduce an automated quality control to ensure that the code does not deteriorate again.
- Introduce processes that help stabilize the quality improvement, like reviews etc.
- Introduce a continuous improvement process in the team.
In WebInvest we are observing the following metrics:
- Package cycles
- Average Component Dependency
- Cyclomatic Complexity
- Number of Methods per class
- Lines of code per method
- Compiler warnings
- Test coverage
We used Classycle [CLASS] and Structure101 [STRUC] to check and ensure package cycles and component dependency. This is not automated yet as it would still fail in too many places. To eliminate some of the architectural violation it is planned to separate this big project into several sub-projects. To visualize the code metrics we use Coqua [COQ], a code metrics compilation integrating several tools, which was used by the team lead in several other projects before.

Figure 7: Coqua Dashboard of WebInvest
In our opinion, a very important method to stabilize the changes is to introduce a continuous improvement process. Continuous improvement allows the team to find the specific actions needed to improve their process in such a way that quality can be assured. We experienced that retrospectives are a good start. There, experiments can be defined, which allows the team to try out new things without pressure.
In WebInvest, there were no retrospectives, nor other continuous improvement techniques. They followed a more traditional process with four releases a year. To introduce continuous improvement, we started with retrospectives after releases. In these retrospectives we defined actions as experiments. Defining experiments allows the team to try something new without being forced into it. Changes are only adapted to the process if they are approved by the team. In WebInvest, the first retrospective resulted in the following experiments:
- To improve the daily stand-up meeting
- To improve the estimation process
- The introduction of a story board
Although we think that agile methods are fundamental to successful software development, it is important to only suggest changes that fit the team - and to keep in mind that there is always resistance to change. This means that one has to leave enough time for trying new things, and to adjust the planning accordingly. Nevertheless, we think that the introduction of a continuous improvement is necessary to stabilize the code quality.
Continuously fighting Deterioration
When does a refactoring project actually end? Ideally, it ends when all the findings of the assessment have been realized. More often, however, it will end when funding ends. As we already pointed out in the stabilization section, it is important to introduce a continuous improvement process to prevent the project from falling into the infeasibility stage again. As an additional measure, we strongly recommend to have regular external reviews that monitor the state of the application.
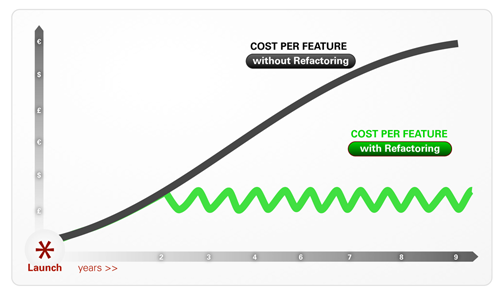
Figure 8: Constant refactoring controls the cost per feature
Depending on the awareness and the knowledge of the application developers, it can also make sense to add consulting for the development of new features. Architectural or design flaws are easier to fix before they are actually implemented. Of course, bringing in external expertise does not only make sense in refactored projects: it can be helpful in any project.
Conclusion
Refactoring large software systems is expensive and time consuming. It is very difficult to estimate how much time will be needed. Compare it to renovating an old house: even if you investigate carefully what needs to be renovated and try to estimate the cost, there will be unpleasant surprises once you have actually started, and you can easily run out of budget. After the assessment, usually an estimate of the cost of the project is required. Unfortunately, it is not possible to foresee everything, no matter how much time you invest in analyzing. Thus, it is important to find an agreement with the customer that allows them to get most out of the refactoring. One successful way to tackle this problem is to fix a maximal amount for the project and to work on a time and material basis. This approach needs the actual refactoring tasks to be prioritized. The project management should be aware that priorities may change and re-planning may be needed.
Organizing and planning the project is as important as improving the source code. Agile techniques support constant re-planning and a disciplined way of working. Focusing on the actual tasks, defining criteria when a task is finished, working in pairs of mutual reviewers, all this is essential to tackle large refactoring projects and to ensure consistency as well as unaltered behavior of the application.
If applications are considered important enough to undergo a large refactoring, there are feature requests waiting to be implemented for which time to market is critical. One big advantage of refactoring over rewriting is that refactoring and the implementation of new features can be done in parallel. In WebInvest the implementation of a crucial new feature (analyzing the risk of the portfolio) started at the same time as the first part of the refactoring. The problem with this particular feature was that it had to be integrated tightly into the existing application and could not be realized as a separate module. Without the new design of the service layer (service oriented, facades, immutable transfer objects, abstraction of the back end service) it would not have been possible to implement this feature in time. Parallel development of new features and refactoring is also valuable to the refactoring team because of the feedback gained.
Sometimes it is inevitable to make compromises when maintaining an application. These compromises must be monitored carefully and replaced with a proper implementation as soon as possible to fight deterioration.
One of the most important lessons we learned from WebInvest was the fact that it can be helpful to start out with structural refactoring only. This means that one only tries to improve the structure of the code, not the way things are implemented. In WebInvest, for example, even though we noticed very quickly that the backend services were not used in the most effective way, we did not change them in the first part of the refactoring. Only when the first part was completed and, thus, many side effects had been removed, we started to address them. The improved readability made these changes easier to implement and less risky.
Other lessons we learned:
- Favor simplicity over complexity - KISS (keep it simple stupid) applies to refactoring projects too
- Transfer knowledge to the developer team as early as possible
- Integration tests are more valuable than unit tests
- Continuous Integration is a must
- Introducing continuing improvement processes and involvement of the team in the refactoring improves the overall acceptance.
Finally, even though the refactoring of WebInvest is not completed yet, it is already considered a success because the implementation of new features is possible again.
References
[Bloch] Joshua Bloch, Effective Java, Second Edition, Addison-Wesley, 2008
[ChFowl] Chad Fowler, http://chadfowler.com/2006/12/27/the-big-rewrite
[DbC] http://en.wikipedia.org/wiki/Design_by_contract
[Facade] http://en.wikipedia.org/wiki/Facade_pattern
[Fowl] Martin Fowler, Refactoring, Improving the Design of Existing Code
[CLASS] Classycle, http://classycle.sourceforge.net/
[CWT], Canoo Webtest, http://webtest.canoo.com/webtest/manual/WebTestHome.html
[COQ] Coqua, http://sourceforge.net/projects/coqua/
[STRUC] Structure 101, http://www.headwaysoftware.com/products/structure101/index.php
[TEAM] Teamcity, http://www.jetbrains.com/teamcity/
Related Software Architecture articles
When Good Architecture Goes Bad
Chop Onions Instead of Layers in Software Architecture
Simple Sketches for Diagramming your Software Architecture
Related Software Architecture videos
Click here to view the complete list of archived articles
This article was originally published in the Winter 2009 issue of Methods & Tools
|
Methods & Tools Software Testing Magazine The Scrum Expert |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


