|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Automated Testing Strategy for a Microservices Architecture
Emily Bache, Praqma, @emilybache, http://coding-is-like-cooking.info
Formerly at Pagero, https://www.pagero.com/
I've written before about our journey from a Monolith to a Microservices architecture and efforts to achieve Continuous Delivery. One part of that journey that I've been very involved in is the evolution of our automated end-to-end system tests. It turns out that having lots of microservices opens up new ways to design these tests. We found we could make them faster and easier to debug, as well as having less test code to maintain. I'm quite proud of the approach we've come up with and I thought others might be interested to hear about it.
Before we started with microservices, we had a relatively simple test structure for the monolith. We were testing at various levels, mostly according to the standard testing pyramid:
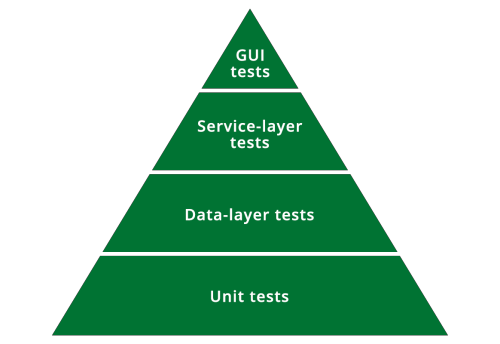
Figure 1: Our testing pyramid before we introduced microservices.
Most of the test cases were unit tests, at the class and method level. Over that, we had quite a few tests focused around the data access layer, using a fairly fine-grained API to check the ORM integration with the database. Then there were some higher-level tests that accessed an API to test whole features. Then came the end-to-end tests, testing the full stack via the GUI.
This was working pretty well when I arrived just over three years ago. The trouble was, new functionality was being built in external microservices, and we needed some way to test them together with the monolith. Each new microservice of course had its own tests – mostly unit tests, but also a few tests for the whole service running in isolation of the others. Testing the pieces like that, only gets you so far, though. The higher levels of the testing pyramid are also needed, and that's where our bottleneck seemed to be.
“Having lots of microservices opens up new ways to design automated end-to-end system tests.”
Pain points with the old system tests
The thing was, the old service-level tests weren't very easy to read or understand, and they were a lot of work to maintain. The GUI tests were in better shape, using modern tools, with a good structure. But actually, GUI tests are always expensive to maintain and run, and it turns out a lot of the functionality in our system is provided primarily via APIs, not the user interface.
I thought we should probably be looking to expand our service-layer API tests to cover the new microservices too. I was experimenting with different ways to do this, when we ran into the killer problem with these old tests – when we ran them in the new microservices architecture, they suddenly got 10 times slower!
When the tests could be run in the same JVM as the entire monolithic system, everything was fine. The tests accessed the functionality using RMI calls. As if by magic, the application server converted all these remote calls into local calls. It all changed when we introduced microservices though.
We had to deploy the monolith in its Docker container alongside all the others, and suddenly the tests were in a different JVM. All those hundreds of RMI calls immediately became an order of magnitude slower, as the application server no longer optimised them away. What's more, we found we had to rebuild the tests every time we rebuilt the system, since the client end of an RMI call must exactly match the server version. It was all getting rather difficult to manage, and the tests no longer took 20 minutes to run, it was more like 2 hours.
So I proposed that we should build a new suite of API tests, that would be designed to work in a microservices architecture from the ground up. They should be faster to run, cheaper to maintain, and easier to find the root cause when something failed. Quite a shopping list! This is what I came up with:
Strategy for the New System Tests
The new tests access all the services using REST, which is a much more flexible and universal way to make remote calls than Java RMI. Each test case also listens to all the messages being sent between the various microservices while it processes the test request. This enables us to track the progress of a test while it's running, and if it fails, make it easier to work out at what point it went wrong. It also means the test can react to events in the system, and trigger exceptional workflows.
Those decisions were quite obvious in a way, that the tests should speak the same language as the microservices. By doing that, the tests naturally ran more quickly, and were easier to debug. I felt we could do more to reduce the maintenance burden though. To that end we decided they would also be Data-Driven, and use Approval testing.
“The new tests access all the services using REST, which is a much more flexible and universal way to make remote calls than Java RMI.”
Data-Driven Testing
Data-Driven Testing means you generally keep the workflow the same, but vary the data from case to case. This minimizes the amount of new code per test case, since most of the time it is enough to change the input data in order to exercise a new or updated feature. In the case of Pagero Online, the most important use case is sending a document from an Issuer to a Recipient. So this is the use-case that almost all our tests exercise.
Within that basic premise, that a test comprises an Issuer, a Recipient, and a Document being sent between them, there are a host of variations that you need to cover. If you look at our test cases, essentially all of them are based around these three elements.
We define them in structured text files separate from the fixture code that performs the use case. The fixture code parses the text files, makes REST calls to create the corresponding Issuer and Recipient in the system, then makes a request to Pagero Online on behalf of the Issuer to send the document to the Recipient.
Defining a new test case is often just a matter of defining a different configuration for these three entities. It's only if you need a significant variation on that basic use-case that you need to go in and write any new test fixture code.
Approval Testing
Approval Testing refers to the way you determine whether a test has passed. You may be familiar already with Assertion-Based Testing, where you have to decide in each test case what the correct behaviour is, by making assertions about the output you require. In Approval Testing, you instead compare the current output with an 'Approved' version of that output, that was gathered in a previous test run. Any difference between the actual output and the approved version is marked as failure.
So with Pagero Online, we store an approved version of the document that is presented to the Recipient. We also store an approved version of the list of messages that were passed between the services while the document was being processed, and any error logs related to it. By examining all those different kinds of output from Pagero Online, we can be confident the document was processed correctly.
This approach has several advantages, particularly when used together with Data-Driven testing. You mostly don't have to write assertion code that is specific to a certain test case, reducing the amount of test code further. What's more, because every test is actually checking quite a large number of things, you end up finding bugs you didn't anticipate when you wrote the test. For example, discovering a stray extra message being sent that shouldn't be, or a formatting error on page three of the document presentation.
New system tests replacing the old ones
It took a few months, but eventually the new system tests started to prove themselves to be useful testing new functionality we had built. Over the following two years or so, we did a lot of work replacing the old tests with new ones – and we're not finished yet actually. In accordance with the 80/20 rule, that last 20% of them seems to be taking an inordinately long time.
In the meantime, I think we've shown the new approach to automated system tests has been largely successful in the aim of reducing test maintenance, while being effective and running quickly. Because they execute in parallel, we can make the tests run faster by adding hardware. Usually it takes about 15 minutes to get results.
“I think we've shown the new approach has been largely successful in the aim of reducing test maintenance, while being effective and running quickly.”
The overall picture
Looking at the full picture of all our testing activities, we still have many unit tests, those are the cheapest and simplest to maintain. Each microservice has whole-service tests that prove it works in isolation, when calls to other services are stubbed out. The next level of testing is the new system tests, which run all the services together, and then the GUI tests which test the whole stack. If all those automated tests pass, we have some manual tests and some further regression tests before the release candidate is ready to be deployed.
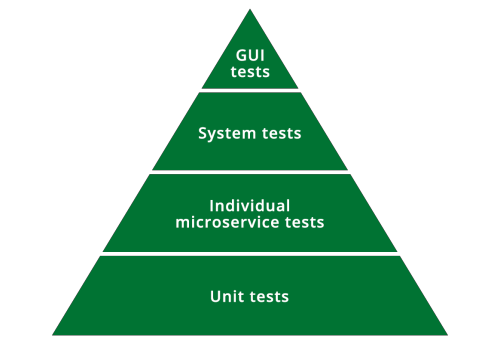
Figure 2: Testing pyramid including our microservice tests and new system tests.
Actually, it's a little more complex than I just made it sound. Configuration management of all those microservices and the test cases that exercise them is decidedly more complex than I imagined when we started! Instead of having a new version of one monolith to test, you have new versions of loads of microservices to co-ordinate and it is not a trivial problem.
Microservices architecture changes how you run your system tests
It turns out that that having lots of independent microservices being built by independent teams changes the way you need to build and run your system tests. Configuration management becomes crucial when you have so many moving parts to test and deploy.
We've actually been through a couple of iterations of our deployment pipeline structure. To start with, we ran all the new system tests against the whole system every time anything changed in any service anywhere.
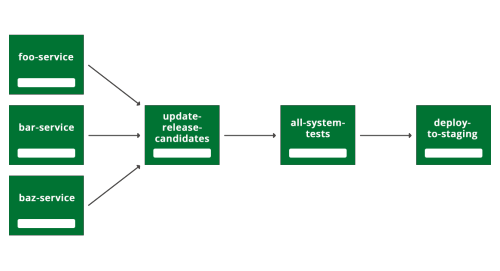
Figure 3: First build pipeline structure we tried (foo, bar and baz are placeholder names for our actual service names, and of course in reality we had more like 20 or so different services).
If you look at Figure 3, you can see the first way we arranged our build pipeline. When anyone pushes to any of the services (foo, bar or baz service) it triggers a new build of 'update-release-candidates' which updates the list of all the latest versions of all the services. Then we test these versions of the services running at the same time, in all the all-system-tests pipeline. If they all pass, then the 'deploy-to-staging' pipeline becomes available to run (we actually trigger it manually so we don't disturb other work going on there).
There were several problems with this structure. Firstly, the tests couldn't keep up with the number of changes being generated by our developers. Quite often a pile of tens of changes would all go into the all-system-tests pipeline together, and it would be hard to work out which one had caused a test breakage. While the tests were broken, we got no new release candidates of the system at all, so everyone was blocked from deploying their changes.
"Having lots of independent microservices being built by independent teams changes the way you need to build and run your system tests."
The dashboard
One solution we tried for this problem was to improve our analysis tools. We had a couple of bright young summer students help us to improve our 'dashboard' web application to analyse failing tests (it's free and open source by the way – available here).
When the tests fail, it shows you all the commits that could possibly have caused it, going all the way upstream in the pipeline. It then lets you assign the task of fixing the tests to someone appropriate. This did help quite a bit, it got much easier to work out what was happening, which service had a problem, and who should fix it.

Figure 4: Second pipeline structure we tried. The system tests are now divided up by feature area ("FeatureA", "FeatureB" are placeholders for the actual feature names, and of course in reality we had a lot more than two of them).
We also divided up the system tests into several suites by feature. Mostly this was because the number of microservices was so large, you couldn't run all of them on the same machine any more. So each featureX-system-tests run will start a subset of the microservices, and run tests against one functional area that can be handled by only those services. This helps us to pinpoint which functional area is broken, and therefore which team should fix them.
The trouble was, it didn't seem to increase the number of release candidates very much. People still broke tests, and even though we could quickly discover who it was who should fix them, failing tests were still blocking our pipeline too often. It becomes easier to see why that is, if I draw the same pipeline diagram again, but highlighting which teams owned which parts (Figure 5).
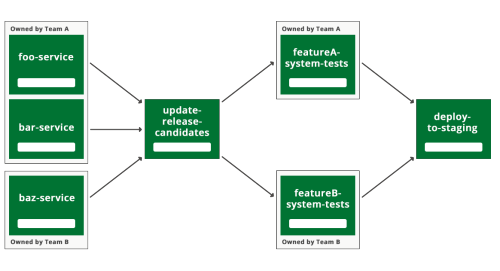
Figure 5: Same diagram as figure 4, but with team ownership added (in reality our teams have much better names than 'A' and 'B' and we have a lot more of them).
It's clear from Figure 5 that if Team B make a mistake in the 'baz-service' that breaks the 'featureB-system-tests' then this will block Team A from getting any new versions of their services into staging.
"It's all about understanding that we live in a microservices architecture now, and microservices need to be compatible with both older and newer versions of the other services."
Independent Teams with shared tests
We had split up our functionality across many services. We had split up our developers into independent feature teams. The tests were formally owned by different teams. It wasn't enough! The problem was that a mistake by one team in one service would block all the other teams from deploying their services. So we changed to a pipeline structure as in Figure 6.
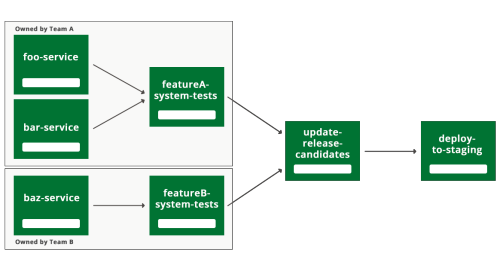
Figure 6: Latest pipeline structure we're using.
This change wasn't as simple as it looks on the diagram. In system tests, because you're testing whole features, you'll necessarily be running several microservices. Team A needs to also use the services owned by Team B when they run their featureA-system tests. Crucially though, they don't need the very latest version.
We created a new definition of the 'release candidate' version of a service. This is the version that has passed all the system tests owned by the team that develops it. In future we might expand that definition to be more stringent, perhaps even that it is a version that is already released in production, but for the moment, a 'release candidate' has passed its own team's portion of the system tests.
So when Team A is going to run the system tests, they use these 'release-candidate' versions of all the other teams' services, together with the development versions of their own. If the tests pass, then these development versions of team A's services get promoted to 'release candidate' status, and the other teams start using them in their system tests.
Crucially, if team A introduces a change in one of their services that break their system tests, it should only stop team A from deploying their service. All the other teams keep running with the 'release candidate' version.
Of course it can still happen that a release candidate version of Team A's services can break the tests owned by Team B, and block them, but we think it should happen a lot less often. Team A's services have at least been shown to pass some system tests. It also ought to be pretty straightforward for Team B to go back to using the previous release candidate version, and get their tests passing again. In the meantime, Team A can improve their tests to catch this problem discovered by Team B.
Generally, it's all about understanding that we live in a microservices architecture now, and microservices need to be compatible with both older and newer versions of the other services.
This move to decentralized system tests has been implemented quite recently, and I'm sure there are going to be further tweaks and improvements to this pipeline structure. As I mentioned before, the definition of 'release candidate' may be changed to 'version in production'. We may also find it useful to run all the system tests again before release, against staging. Alternatively we may discover we find no new bugs that way, and it's not worth it. In any case I'm confident the change I've just described is a useful one. What we have now is much more in tune with our microservices architecture and our feature-team organization.
"After a few iterations we've landed with a pipeline structure that is more in tune with a microservices architecture."
Conclusions and lessons learned
Compared to when we had a monolith, our pyramid of tests is still the same shape, but each team has a separate slice of it to care for. The initial structure for system tests was actually pretty similar to how it would have looked in the days when we had a monolith to test. We ran all the tests against the latest versions of all the services. This didn't work too well, one team could break some tests and block all the other teams from deploying.
After a few iterations we've landed with a pipeline structure that is instead more in tune with a microservices architecture. The system tests are divided by team, and each team's changes are tested together with the release candidate versions of all the other teams' services. Generally, we feel confident that we're moving in the right direction, and the automated test strategy we've chosen for our microservices architecture help us achieve our aim to continuously deliver a constantly improving Pagero Online to our customers.
This article was originally published on Pagero blog and is reproduced with permission from Pagero
Software Testing Resources
Software Testing Videos and Tutorials
Click here to view the complete list of archived articles
Article published in March 2017
|
Methods & Tools Software Testing Magazine The Scrum Expert |
|
Discover the best available Open Source Project Management Tools (Gantt, Scrum, Kanban) Explore a list of Free and Open Source Scrum Tools for Agile Software Project Management |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


