|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Click here to view the complete list of archived articles
This article was originally published in the Spring 2011 issue of Methods & Tools
Managing Schedule Flaws using Agile Methods
Brian Button, VP Engineering, Asynchrony Solutions, Inc., www.asolutions.com
Software projects rarely come in both on time and on budget leading to dissatisfied end users. It’s much easier to satisfy one of the above conditions by working according to your original plan or adapting to the changing needs of your users. Satisfying both requires a certain amount of prescience. Demarco and Lister, authors of "Waltzing with Bears: Managing Risk on Software Projects," list Schedule Flaws as one of their 5 Risks of Software Project Management.
In this article, we’ll discuss several symptoms and causes of schedule flaws, present metrics and diagrams that can be used to track your team’s progress against its schedule, and describe Agile ways to address these risks.
The risk of schedule flaws refers to the certainty that any schedule created at the start of a project will be hopelessly out of date by the end of that project, and should not be counted on as an accurate projection of completion date, content, or cost. With the uncertainties and intangibles of software, it does not matter how much time and effort is put into creating the schedule at the start of a project, as the schedule will certainly change along the way.
Causes
There are two different categories of causes for schedule flaws. The first category is directly related to unpredictability of the environment around a project; including the people, hardware and network issues, vacation schedules, weather, and other causes that directly affect the rate at which work can be done. The second category is related to the difficulty in accurately predicting the time significant pieces of software will take to implement, test, and be ready for deployment.
Environmental issues are particularly tricky because they are unpredictable. People get sick, snow storms happen, and fiber gets cut occasionally. These usually aren’t a huge drag on your project and are generally outside of your control. However, their effects should be considered and anticipated. Also related to this category, and in your control, are the quantity and lengths of meetings that occur which pull people away from system development. If there is one item that can kill the productivity and morale of a good team, it’s the multiple meeting mania that occurs in some cultures.
Regarding the second category, the time issue is just a fact of life. Software is incredibly complex, it is not bound to obeying any laws of nature, and it is made up of lots of independent pieces that have to perfectly fit together into a coherent whole to function properly. Add to that the fact no software plan survives its first contact with the customer, and you’re left with a situation where your plan is going to need to change to keep up with what is really happening. This is the risk that we’ll focus on below.
Symptoms
Teams that suffer from schedule flaws often exhibit one or more of the following five symptoms:
1. Frequent change requests from customers and stakeholders
In theory, it seems logical to nail down what the stakeholders for a project want before anything happens on a project. The flaw in this vision is that customers rarely know what they want, especially if the system is new or revolutionary. As soon as they see some piece of the system in action, they’ll start to get ideas, which lead to change requests. Some of these may be new requirements that they’ve just discovered, and some may be refinements on work that has already been done. In either case, this results in new work that was unknown at the start of the project.
2. Unreliable estimates
Every interesting piece of software that gets built is inherently something new. Because of this, the time to build individual pieces is difficult to accurately estimate. Even in a well-understood domain, the particular solutions chosen by teams are rarely the same twice, because the context in which the project exists is rarely the same twice. There is also a higher probability that a piece of work will be completed significantly after it was estimated rather than before. Inaccurate build estimates can drive the larger project schedule to being late.
3. Large amount of "off the books" work
Teams typically have two sets of work – things that are "on the books" or part of the schedule, and "off the books" work that everyone knows about, no one talks about, and no one factors into the plan. This can include action items like the inevitable activities that have to be done to deliver software, some specialized kinds of testing like load and scalability, or just corners that were cut in the interests of some short term deadline that everyone knows can’t be shipped but no one has planned time to correct. Every team has these, and these don’t usually show up as a schedule flaw until the last days of a project.
4. Uncertain quality
Uncertain quality is a more specific kind of "off the books" work. There are lots of software projects out there that don’t have a good grasp of the quality of their system day to day. They may not do full system builds until late in their project lifecycle, they may do only a limited amount of testing during development, put off performance or security testing until the software is "done," or several other items that delay testing until late in the process. The effect of this is that there is a potential project risk of an unknown amount of work that needs to be done at the very worst time in a project’s lifecycle – at the very end, right before delivery is scheduled.
5. Matrixed team members
Every company has people who have specialized knowledge that are critical for the success of several projects. These staff members may be an architect who consults on several teams; the specialist in performance testing, usability, accessibility, security, or just testers in general. There are also several other roles that teams need in varying degrees. Often times, the company has more work and more teams than it has developers to support them. In an attempt to maximize the utilization of these scarce resources, these people are asked to support several teams at the same time. This results in them becoming a bottleneck in the workflow of not just one team, but to all the teams with which they are working for.
Metrics
Having a good set of historical metrics is key to understanding when schedule flaws are occurring and what their effects have been. The most basic metric used to illustrate schedule flaws is a simple burndown chart. Burndown charts are just graphs of work completed versus time, sometimes with both actual and planned work/timelines shown. A project is on-track as long as the actual progress and planned progress match. A solid metric describing your progress against your desired delivery date is the most critical measurement for a project to keep, since it is the leading indicator of whether you have a problem. Here is an example:
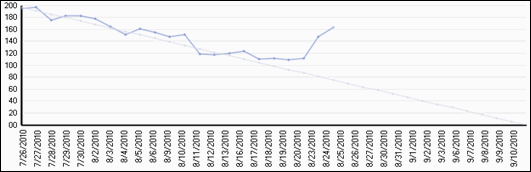
Figure 1 - Example Burn Down Chart
In this diagram, we can see a project that spent several weeks basically tracking the ideal curve down their burndown chart. The net amount of work remaining for this release was steadily decreasing in a way that would let the project complete at a predictable date – in fact, it was proceeding on schedule. All of a sudden, though, the project went off-track. A large amount of work was added to the release, as can be seen by the upwards slope of the burndown line, and the completion date of the project was immediately in trouble. Scope had to be cut or time added to bring the project in successfully.
The above chart is useful for seeing the net amount of work remaining on a project and projecting a completion date, but it does not provide a picture of the amount of working added versus work completed in absolute terms. There are several other kinds of graphs that are good for illustrating this, such as a stacked bar chart showing the amount of work complete versus amount of work remaining.
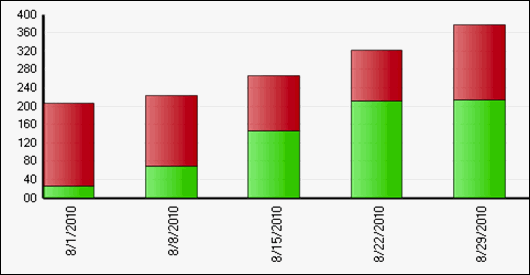
Figure 2 - Example Burn Up Chart
On the above chart, the total height of any bar represents the total amount of work present in the project, while the green represents work completed and the red shows work left to do. In other words, the total scope of the project is constant as long as the height of each bar remains constant in comparison to the others. If the total height grows, then the project has included additional scope. Here, you can see that work is being added as quickly as it is being finished, resulting in a finish line that is constantly moving to the right.
These two graphs show the same backlog for the same project, but illustrate the different information available from each graph.
Metrics to Understand Causes
Once it is determined that the project is not keeping to its schedule, more investigation must be done to determine why that is. Below are several metrics that can be used to learn about underlying causes of schedule flaws.
1. Changing Capacity
If the amount of work being completed by a team is very inconsistent from period to period, one potential reason may be that the available bandwidth of the team is changing rapidly over time. If specific team members are matrixed into several teams, it is possible that their lack of attention during some work weeks may slow down the team. In this case, a simple graph of total available hours per day or per sprint would be enough to identify the issue. Below is an example.
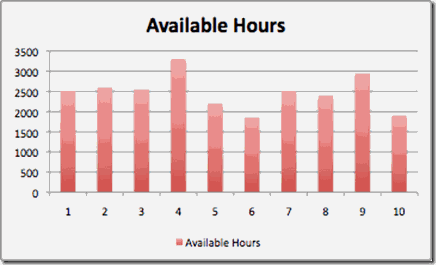
Figure 3 - Capacity per Sprint
Clearly there are issues with consistency of the workforce associated with this team, and further investigation would be needed to determine why the number of hours varied so greatly. Regardless of why it is happening, this team’s velocity is likely to vary quite a bit from iteration to iteration.
2. Poor Estimation Accuracy
Judging estimation accuracy is one of the more tricky aspects of analyzing metrics. Is it more important for a particular estimate to be correct, or more important for the overall estimate to be correct over a larger number of features? On a recent project I managed, we kept track of estimates versus actuals (my first time doing this). What we learned is that we were really bad at individual feature or story estimates, but we were really good at creating estimates that came out fairly accurately when taken as a whole. In other words, individual estimates were over or under by a considerable amount, but the errors tended to cancel each other out in a way that made the aggregate estimate pretty accurate!
The most important part of looking at estimation accuracy is identifying stories that are outliers from the main body of the estimates and trying to understand what made them off by so much. What I did on this project is to gather all the stories with the same estimates (in our case, between 1 and 8 "points") and plot the number of stories that came in at a particular number of actual hours. Here is my graph for features rated 1 point:
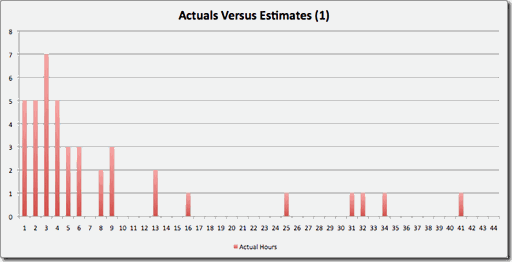
Figure 4 - Estimates versus Actuals for 1 Point Stories
The Y axis in this graph represents the number of features that were finished in the given number of hours as seen along the X axis. For our project, we had planned on a single point being equivalent to 4 hours of work, so, for the most part, features of 1 point were estimated pretty accurately (most of them were 1 to 6 hours). There are quite a few estimates that were less than 4 hours, mostly because we didn’t deal in fractional hours in our estimates, which made a 1 point estimate the smallest we could create. However, there were a number of outliers that served to be good topics of conversation. In many of the cases, there were good reasons for the time it took, such as defects uncovered in existing, legacy code or unclear requirements.
Similar graphs were created for stories of larger complexity and estimates. As one would expect, as the estimates for stories grew larger, the uncertainty in the estimates grew larger as well. The important lesson that the team learned from this was that they were much better at accurately estimating smaller stories than larger ones. For example, just doubling the story estimate drastically changed the distribution of estimates, as seen in Figure 5.
As can be seen from the graphic below, the largest peak in actual hours for stories with an estimate of 2 was somewhere around 6 or 7 hours, which matched pretty closely with our intended goal of 4 hours per point. But just increasing the story size by this much allowed more uncertainty to creep into the estimates, creating far more outliers.
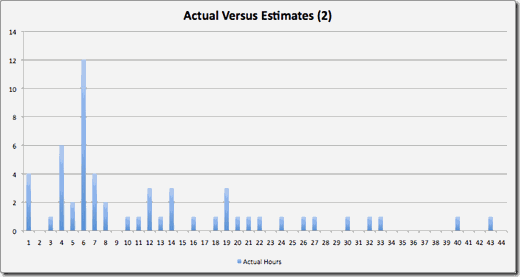
Figure 5 - Estimates versus Actuals for 2 Points Stories
3. Uncertain Quality and "Off the Books" Work
As stated previously, these two symptoms are insidious. I know of no way to measure either of them directly without introducing large-scale process changes (as Agile is going to do, a little at a time and as described below). On teams with whom I’ve been associated, these two reasons are known by everyone on the team but acknowledged by no one. The best way to understand the effects of these two flaws is for a manager to work closely enough with the team to feel the undercurrent of tension that people are surely experiencing. Faced with this undercurrent, they must start conversations about quality and completeness and readiness. The longer the team waits to have these conversations, the more unpleasant the surprise at the project’s end.
Agile Planning & Roadmaps
Perhaps unsurprisingly, the point of this whole article is that being Agile, thinking Agile, and acting in an Agile manner, you’ll never feel any of the above pains and your projects will always deliver exactly on time, on budget, and have exquisite quality. Well, at least that’s the theory… in practice, however, you’ll have the knowledge to allow you to come pretty close.
Agile teams plan differently. They absolutely have a plan and a schedule, but the plan is expected to change over time. Planning becomes a commonplace activity, performed at different levels and at different rhythms throughout a project. Planning is done as a way of managing risks throughout the execution of a project. These different levels of planning serve to address each of the issues described above in specific ways.
At the highest levels, Agile teams plan for delivering capabilities to customers at some agreed upon schedule. These capabilities are loosely defined to leave as much wiggle room as possible while giving as complete a description of the feature as possible. This wiggle room sounds absurd on the surface, but it is actually a key ingredient of what makes this style of planning so successful – we’ll talk more about that shortly.
The output of this planning is a roadmap of capabilities that will be delivered at specified times in the future, with some amount of detail about what each capability will provide. That should be enough for long range planning, marketing, and sales. They have a rough roadmap and a near certain guarantee of delivery.
By keeping this long-range planning at a very high level, people are free to make changes in the plan at this point with little cost and with little risk. This level of planning happens several times a year.
Planning & Execution
One level down from roadmap/portfolio level planning is Release Planning. This is when and how teams solidify the features they are going to deliver in the next few weeks, usually 4-12 weeks out. Capabilities from the roadmap are selected and broken down into smaller, more understandable units called Minimal Marketable Features (MMFs). Those features that are selected first tend to be the ones thought to provide the greatest value to business stakeholders, risk reduction, or learning for an organization. Lower-valued features are pushed later in the project schedule, or perhaps fall off completely if their value never becomes high enough to justify the cost of developing them.
MMFs represent the minimal chunk of functionality that an organization can show to users or customers to generate excitement or interest. They can cut across multiple capabilities, they can touch different areas of the system, but they always represent something of immediate, marketable value to someone. At this level, they are a bit more well-defined than the epics on the roadmap, but further definition is intentionally being deferred until the details are actually needed. As before, detailed decisions are intentionally deferred until later. The reason decisions are deferred is that deciding early increases the risk of being wrong. Delaying decisions allows time to learn as much as possible before a decision is made, increasing the chances of making the right choice. The theory behind this is embodied in the Lean principle of the Last Responsible Moment.
The MMFs are estimated by the practitioners who are going to implement them, and they are prioritized according to their importance to the release. This level of planning happens once per release, so between 4-12 times a year.
The most frequent form of planning, iteration planning, happens once every week or two and is where the rubber finally meets the road. A small number of MMFs is brought to the team, where they are broken into "user stories," small bites of functionality that provide some portion of the MMFs features. The key characteristic of these user stories, however, is that they still provide some level of excitement to a stakeholder or user of the system. It is likely to take several stories to add up to a single MMF.
During iteration planning, the team discusses the low level business details of how each MMF works and builds a plan for how they are going to implement the user stories making up the MMFs in the iteration. Each story is defined as concretely as possible, including a set of acceptance criteria that detail what it means for that story to be done. These acceptance criteria are used as the standard in determining when a story is complete, providing a measurable and definite end to the story. This prevents an unmeasured and unspoken amount of work left to be done later in a project. Finally, as the final step, every user story is estimated. At this point, these finely grained units of work are generally a day or less of work. As described above, smaller stories are estimated more accurately.
As part of the capacity planning used during iteration planning, historical values for the capacity of the team are tracked and used to limit the amount of work promised for the 1-2 week time box. This regular rhythm of planning, committing, executing, and delivering gives the project a heartbeat that allows its progress to be measured and tracked.
The final piece of the puzzle is execution. This involves dealing with the causes of schedule flaws that happen during the creation of the software. Every single person on the team commits to creating a quality product, from the first user story to the last line of code. Everyone runs, everyone tests, and everyone owns quality. Quality is never uncertain on a team like this. Each move that a team member makes is done with an eye on producing quality. There are automated tests around everything, including security, load, scalability, and performance. Most tests are run dozens of times a day, and every test is run at least once per night. The system is continuously built, deployed, and tested.
Obviously, there is effort expended to reach these quality levels. But the benefit of this effort is that a team can be ready to ship code at any time. Any feature that is done is really done. It is coded, tested at the feature and system level, all needed documentation is written, and it is ready to go. This lets progress through the project be tracked in terms of completed value, and allows for early and incremental delivery of working functionality.
By focusing on the agile practices and metrics detailed in this article, teams can identify and manage those risks that cause schedule flaws. These metrics give visibility to the risks, while the practices give teams tools to manage those risks. Between the combination of the two, teams can deliver value to their stakeholders quickly, effectively, and with high quality. And delivering value is what we’re here for, isn’t it?
Related Articles
Project Failure Prevention: 10 Principles for Project Control
Measuring Integrated Progress on Agile Software Development Projects
Related Resources
|
Methods & Tools Software Testing Magazine The Scrum Expert |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


