|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
An Introduction to Domain Driven Design
Dan Haywood, Haywood Associates Ltd, http://danhaywood.com/
Today's enterprise applications are undoubtedly sophisticated and rely on some specialized technologies (persistence, AJAX, web services and so on) to do what they do. And as developers it's understandable that we tend to focus on these technical details. But the truth is that a system that doesn't solve the business needs is of no use to anyone, no matter how pretty it looks or how well architected its infrastructure.
The philosophy of domain-driven design (DDD) - first described by Eric Evans in his book [1] of the same name - is about placing our attention at the heart of the application, focusing on the complexity that is intrinsic to the business domain itself. We also distinguish the core domain (unique to the business) from the supporting sub-domains (typically generic in nature, such as money or time), and place appropriately more of our design efforts on the core.
Domain-driven design consists of a set of patterns for building enterprise applications from the domain model out. In your software career you may well have encountered many of these ideas already, especially if you are a seasoned developer in an OO language. But applying them together will allow you to build systems that genuinely meet the needs of the business.
In this article I'm going to run through some of the main patterns of DDD, pick up on some areas where newbies seem to struggle, and highlight some tools and resources (one in particular) to help you apply DDD in your work.
Of Code and Models...
With DDD we're looking to create models of a problem domain. The persistence, user interfaces and messaging stuff can come later, it's the domain that needs to be understood, because that's the bit in the system being built that distinguishes your company's business from your competitors. (And if that isn't true, then consider buying a packaged product instead).
By model we don't mean a diagram or set of diagrams; sure, diagrams are useful but they aren't the model, just different views of the model (see Figure). No, the model is the set of concepts that we select to be implemented in software, represented in code and any other software artifact used to construct the delivered system. In other words, the code is the model. Text editors provide one way to work with this model, though modern tools provide plenty of other visualizations too (UML class diagrams, entity-relationship diagrams, Spring beandocs [2], Struts/JSF flows, and so on).
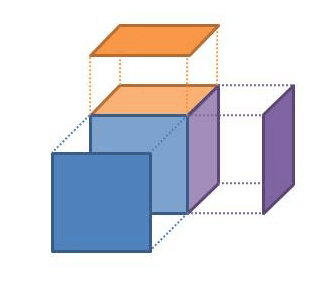
Figure 1: Model vs Views of the Model
This then is the first of the DDD patterns: a model-driven design. It means being able to map - ideally quite literally - the concepts in the model to those of the design/code. A change in the model implies a change to the code; changing the code means the model has changed. DDD doesn't mandate that you model the domain using object-orientation - we could build models using a rules engine, for example - but given that the dominant enterprise programming languages are OO based, most models will be OO in nature. After all, OO is based on a modelling paradigm. The concepts of the model will be represented as classes and interfaces, the responsibilities as class members.
Speaking the Language
Let's now look at another bedrock principle of domain-driven design. To recap: we want to build a domain model that captures the problem domain of the system being built, and we're going to express that understanding in code / software artifacts. To help us do that, DDD advocates that the domain experts and developers consciously communicate using the concepts within the model. So the domain experts don't describe a new user story in terms of a field on a screen or a menu item, they talk about the underlying property or behaviour that's required on a domain object. Similarly the developers don't talk about new instance variables of a class or columns in a database table.
Doing this rigorously we get to develop a ubiquitous language. If an idea can't easily be expressed then it indicates a concept that's missing from the domain model and the team work together to figure out what that missing concept is. Once this has been established then the new field on the screen or column in the database table follows on from that.
Like much of DDD, this idea of developing a ubiquitous language isn't really a new idea: the XPers call it a "system of names", and DBAs for years have put together data dictionaries. But ubiquitous language is an evocative term, and something that can be sold to business and technical people alike. It also makes a lot of sense now that "whole team" agile practices are becoming mainstream.
Models and Contexts ...
Whenever we discuss a model it's always within some context. This context can usually be inferred from the set of end-users that use the system. So we have a front-office trading system deployed to traders, or a point-of-sale system used by cashiers in a supermarket. These users relate to the concepts of the model in a particular way, and the terminology of the model makes sense to these users but not necessarily to anyone else outside that context. DDD calls this the bounded context (BC). Every domain model lives in precisely one BC, and a BC contains precisely one domain model.
I must admit when I first read about BCs I couldn't see the point: if BCs are isomorphic to domain models, why introduce a new term? If it were only end-users that interacted with BCs, then perhaps there wouldn't be any need for this term. However, different systems (BCs) also interact with each other, sending files, passing messages, invoking APIs, etc. If we know there are two BCs interacting with each other, then we know we must take care to translate between the concepts in one domain and those of the other.
Putting an explicit boundary around a model also means we can start discussing relationships between these BCs. In fact, DDD identifies a whole set of relationships between BCs, so that we can rationalize as to what we should do when we need to link our different BCs together:
- published language: the interacting BCs agree on a common a language (for example a bunch of XML schemas over an enterprise service bus) by which they can interact with each other;
- open host service: a BC specifies a protocol (for example a RESTful web service) by which any other BC can use its services;
- shared kernel: two BCs use a common kernel of code (for example a library) as a common lingua-franca, but otherwise do their other stuff in their own specific way;
- customer/supplier: one BC uses the services of another and is a stakeholder (customer) of that other BC. As such it can influence the services provided by that BC;
- conformist: one BC uses the services of another but is not a stakeholder to that other BC. As such it uses "as-is" (conforms to) the protocols or APIs provided by that BC;
- anti-corruption layer: one BC uses the services of another and is not a stakeholder, but aims to minimize impact from changes in the BC it depends on by introducing a set of adapters - an anti-corruption layer.
You can see as we go down this list that the level of co-operation between the two BCs gradually reduces (see Figure 2). With a published language we start off with the BCs establishing a common standard by which they can interact; neither owns this language, rather it is owned by the enterprise in which they reside (it might even be an industry standard). With open host we're still doing pretty well; the BC provides its functionality as a runtime service for any other BC to invoke but will (presumably) maintain backwards compatibility as the service evolves.
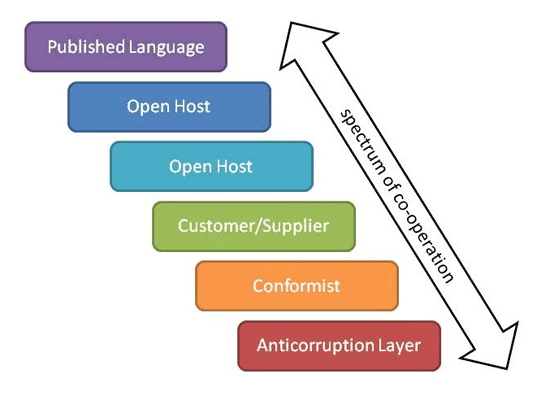
Figure 2: Spectrum of Bounded Context Relationships
However, by the time we get down to conformist we are just living with our lot; one BC is clearly subservient to the other. If we had to integrate with the general ledger system, purchased for megabucks, that might well be the situation we'd live in. And if we use an anti-corruption layer then we're generally integrating with a legacy system, but introduce an extra layer to isolate ourselves as best we can from it. That costs money to implement, of course, but it reduces the dependency risk. An anti-corruption layer is also lot cheaper than re-implementing that legacy system, something that at best would distract our attention from the core domain, and at worst would end in failure.
DDD suggests that we draw up a context map to identify our BCs and those on which we depend or are depended, identifying the nature of these dependencies. Figure 3 shows such a context map for a system I've been working on for the last 5 years or so.
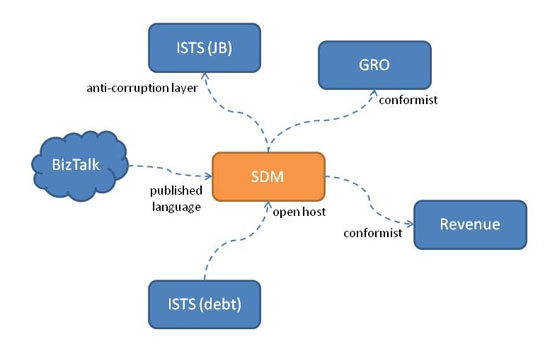
Figure 3: Context Mapping Example
All this talk about context maps and BCs is sometimes called strategic DDD, and for good reason. After all, figuring out the relationship between BCs is all pretty political when you think about it: which upstream systems will my system depend on, is it easy for me to integrate with them, do I have leverage over them, do I trust them? And the same holds true downstream: which systems will be using my services, how do I expose my functionality as services, will they have leverage over me? Misunderstand this and your application could easily be a failure.
Layers and Hexagons
Let's now turn inwards and consider the architecture of our own BC (system). Fundamentally DDD is only really concerned about the domain layer and it doesn't, actually, have a whole lot to say about the other layers: presentation, application or infrastructure (or persistence layer). But it does expect that they exist. This is the layered architecture pattern (Figure 4).

Figure 4: Layered Architecture
We've been building multi-layer systems for years, of course, but that doesn't mean we're necessarily that good at it. Indeed, some of the dominant technologies of the past - yes, EJB 2, I'm looking at you! - have been positively harmful to the idea that a domain model can exist as a meaningful layer. All the business logic seems to seep into the application layer or (even worse) presentation layer, leaving a set of anaemic domain classes [3] as an empty husk of data holders. This is not what DDD is about.
So, to be absolutely clear, there shouldn't be any domain logic in the application layer. Instead, the application layer takes responsibility for such things as transaction management and security. In some architectures it may also take on the responsibility of ensuring that domain objects retrieved from the infrastructure/persistence layer are properly initialized before being interacted with (though I prefer it that the infrastructure layer does this instead).
Where the presentation layer runs in a separate memory space then the application layer also acts as a mediator between the presentation layer and domain layer. The presentation layer generally deals with serializable representations of a domain object or domain objects (data transfer objects, or DTOs), typically one per "view". If these are modified then the presentation layer sends back any changes to the application layer, which in turn determines the domain objects that have been modified, loads them from the persistence layer, and then forwards on the changes to those domain objects.
One downside of the layered architecture is that it suggests a linear stacking of dependencies, from the presentation layer all the way down to the infrastructure layer. However, we may want to support different implementations within both the presentation and infrastructure layer. That's certainly the case if (as I presume we are!) we want to test our application:
- for example, tools such as FitNesse [4] allow us to verify the behaviour of our system from an end-users' perspective. But these tools don't generally go through the presentation layer, instead they go directly to the next layer back, the application layer. So in a sense FitNesse acts as an alternative viewer.
- similarly, we may well have more than one persistence implementation. Our production implementation probably uses RDBMS or similar technology, but for testing and prototyping we may have a lightweight implementation (perhaps even in-memory) so we can mock out persistence.
We might also want to distinguish between interactions between the layers that are "internal" and "external", where by internal I mean an interaction where both layers are wholly within our system (or BC), while an external interaction goes across BCs.
So rather than consider our application as a set of layers, an alternative is to view it as a hexagon [5], as shown in Figure 5. The viewers used by our end-users, as well as FitNesse testing, use an internal client API (or port), while calls coming in from other BCs (eg RESTful for an open host interaction, or an invocation from an ESB adapter for a published language interaction) hit an external client port. For the back-end infrastructure layer we can see a persistence port for alternative object store implementations, and in addition the objects in our domain layer can call out to other BCs through an external services port.
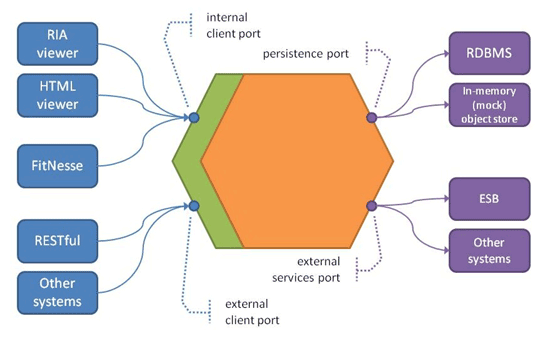
Figure 5: Hexagonal Architecture
But enough of this large-scale stuff; let's get down to what DDD looks like at the coal-face.
|
Methods & Tools Software Testing Magazine The Scrum Expert |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


