|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
What We Learned From Our First Blockchain Software Project
Victoria Lavella, Sebastian Rodriguez, Uruit, https://www.uruit.com/
Working as an outsourced partner for an app using blockchain, we have learned how to overcome several challenges associated with this new technology.
Early this year, a startup called Coinderby, creator of a multiplayer game for breeding, racing, and trading virtual horses using blockchain technology, sought our help to build a singular web application. Although the project was based on the same stack we are already very comfortable working with (Reactjs + Node + GraphQL), it incorporated a new and exciting challenge: this app would be monetized with ethereum! So yes, this would be our first project incorporating blockchain!
At first, we had misguided ideas about blockchain. Once we started working with it we realized things were not exactly as we thought they would be. So we have decided to share our learning process, detailing some of the unexpected challenges we faced and how we solved them along the way.
Challenge accepted: our first blockchain software project!
Before starting, we had no experience working with ethereum blockchain projects. So, yes, there were a lot of new concepts involved that we needed to understand first. Things like what the gas is, how smart contracts work, what is considered a transaction, and so on.
After starting to work with the client in order to understand the project's requirements, we came up with two goals:
- Send transactions from the web application to the blockchain;
- Read the state of the application from the blockchain.
Basically, we spent our first week setting up the architecture for the project and reading about these concepts.
Here's how it went!!
A preconceived idea about blockchain
The mental model in our head was that we needed to do two things on the blockchain: read the data stored by our contracts on the blockchain, being able to sort and filter that data, and solve for the challenge that some events will be triggered automatically by the blockchain at a particular point in time. After all, we thought, this technology is gaining heaps of attention and different people have written about it, so these two things should be really simple (Spoiler... they weren't!).
We'd envisioned that reading data from the blockchain and being able to sort, filter it and so on was something that is probably implemented within the blockchain itself. In fact, it somewhat is, but not in the way someone who is used to working with relational databases would imagine. The reading capabilities are limited to "listening" to events and acting accordingly to what that event triggers. Also, it is possible to filter those events by the parameters they have. However, not much else is possible at the moment.
In addition, our application needs to have some events trigger at a particular point in the future. As a developer who works with any modern language or framework, one would consider that with smart contracts, it is possible to schedule a future execution of a contract function. Something similar to a "cron job" or a scheduled service. At least that is what we initially thought. The reality turned out to be quite different.
The development phase
As we mentioned before, one goal of the web application was to be able to send transactions to the blockchain. The easiest way to accomplish this is by using a plugin called metamask. Most of the applications that interact with the ethereum network are currently using it; the only drawback is that current browser support is limited.
Not only does metamask provide us the API to execute a contract from the browser, it also gives us the ability to sign into our application validating the user's private account key. There are a lot of posts about how to achieve this. that is why our idea was to focus more on the synchronization aspects to be dealt with on the backend.
Nevertheless, the real challenge lay within our second goal. That was to be able, somehow, to get the state of the application from the blockchain. Early in this article we mentioned that ethereum does not allow for traditional database queries such as sorting, paging and filtering. Even if we could do these kinds of queries, we didn't want to rely completely on the ethereum nodes. that is because they can be outdated or the network could be overloaded. The solution for this was to synchronize the application state from the blockchain to a relational database and perform all searches against that database instead.
There are several libraries available for when you need to communicate your backend with ethereum contracts, most of them being wrappers around a library called web3.js. We started to consider some of these wrappers. However, at the end of the day, we decided that web3.js would be the best choice for us.
Our proposed architecture
To connect to a blockchain node there are multiple providers that web3 supports, the most common ones are http and websocket. There are some disadvantages of using http, the main one being that http uses pooling to check events on the blockchain, and the other is that to listen to all the events from a contract, you need to subscribe to them separately. On the other hand, the websocket connection has an "allEvents" method that listens to all the events a contract dispatches. This type of connection also tends to be much more stable.
Unfortunately, some ethereum nodes do not support it. For example, the infura nodes added websocket support recently and in our case, we had some issues maintaining the connection. To overcome this we started on our own ethereum nodes, choosing to use parity, one of the many ethereum clients. The other benefit of having our own nodes was that the connection was much faster because our backend system was on the same network as the ethereum nodes.
The next step after establishing the connection is to start reading from the blockchain itself. To do that, we split the synchronization process into two different phases:
- Synchronization of all past events.
- Real time listening of current events.
Phase 1 is pretty much about when the app starts running
How you can get up to date with all the events that were triggered during the time the app was offline. Achieving this is simple, first you need to know that when you "read" from the blockchain, you are reading "confirmed blocks." At a high level, a block is a storage unit for transaction data - among other important data - identified by a sequential number. Therefore when you need to synchronize the data, you have to indicate to the connection what range of blocks you want to sync.
An initial version of this could be to listen from the block zero to the most recent one. Of course, in terms of performance, that doesn't sound like a good idea. Therefore, our approach was to store the most recent synchronized block and start reading from that block number until the latest one.
Phase 2 is similar to listening to past events
However, instead of reading from one particular block to the most recent, we need to listen to all the events that happen in the blockchain in "real time." We did this by subscribing to the contract "allEvents" method.
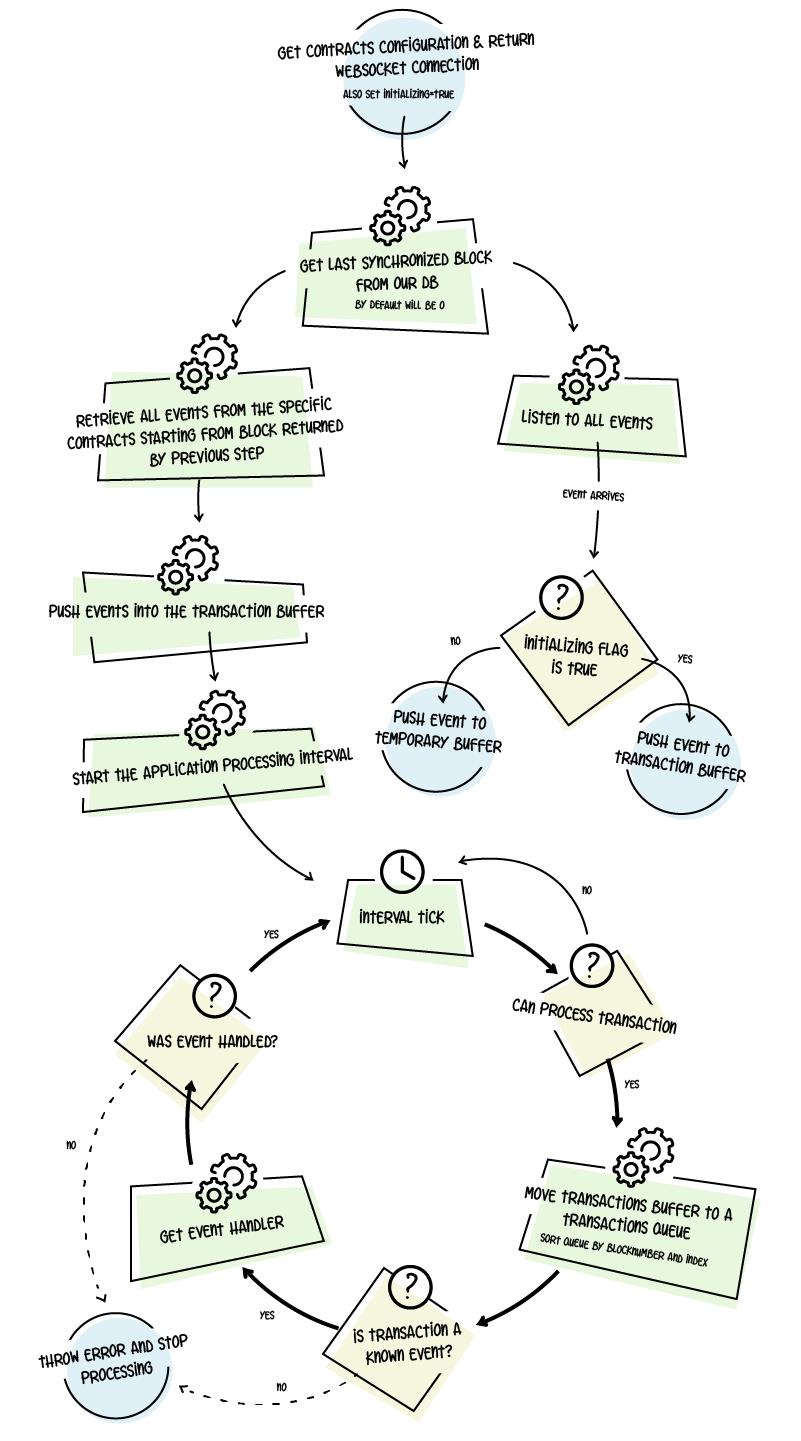
In our implementation, the key to synchronize the database lays in having a transaction buffer, where we push the transactions as they arrive and delay the processing until no further transactions arrive for a short period of time (a few seconds). Once we consider the buffer is stable, we sort all the transactions received by block number and index. That way, we are sure that we have an ordered list of events that happened on the blockchain. After that, we start looping through each transaction and detect the type of action the transaction holds. We do this by reading the events contained within the transaction and then determining what action those events imply (e.g: transfer token / create token).
The next step is iterating over our handlers and passing the action type and the transaction data. Therefore, any handler that wants to process this transaction will pick the corresponding data and update the database accordingly. After iterating through all the handlers, if no handler picked up that transaction, we throw an error and stop the processing. The reason for this is that we might have an unimplemented event in our synchronization process. We cannot keep synchronizing the history of the blockchain if some event is not handled, as that could result in inconsistent data.
This process repeats itself in the lifetime of the application, updating transactions as they arrive.
The following diagram shows a high overview of the process:
Handling "async" events
The last step we had to tackle for this project was the ability to handle certain kinds of async events on the blockchain. By "async events", we mean events that we need to trigger at some point in time without any user interaction with the application. For example, one of the features that Coinderby has is the ability to breed horses. The breeding of a horse is an example of an "async event on the blockchain". that is because after a pregnancy occurs, there is some time that needs to pass before a new horse is born.
As we have mentioned before, our first preconceived idea was that the smart contract will emit some new event when the time arrives. So, by listening to it, we would be able to handle it. Unfortunately, no such thing exists as a programmed job on the blockchain. Therefore we had to implement some logic that would enable us to simulate the asynchronicity.
For us, the key concept to achieve this type of sync was to understand that we could take advantage of the "confirmed block rate" and think of the time in terms of "number of confirmed blocks" instead of thinking of it in terms of "number of seconds elapsed." With a network working in normal conditions, it takes around 15 seconds to mine a new block on the blockchain. With that in mind, we could have a good time estimate and a way to tie both measurement units, "time in seconds" and "number of confirmed blocks."
So, the solution we found is to emit an event from the first transaction with the blockchain -the one that originates the async transaction result- with the number of blocks that the system needs to wait before triggering the async transaction. You can calculate that number using the 15-second average. Finally, we implemented our own job with javascript. It runs with a configurable interval and checks for each "pending async transaction" if we need to trigger it.
The downside of this approach is that when the network is slow, mining a block could take more than 15 seconds. As a consequence, the confirmed block rate will change. Therefore, to use 15 seconds to represent the confirmed block average will likely increase the time that the user needs to wait.
Let's keep learning with blockchain projects
By no means are we blockchain experts nor do we consider this to be a perfect solution. For the problem we had to solve, it worked out pretty well yet there are some limitations to this approach. For example, it could be a challenge to scale it to multiple instances. In our case, this isn't a problem yet due to the ethereum blockchain average mining time. Therefore, we are not processing too many transactions per minute.
From our point of view, the documentation around blockchain is scarce. Also, there is still a lot that needs to evolve in terms of software and library maturity. Most of the libraries we have used for this are still in the beta stage and there is much room to grow.
That said, we have learned an incredible amount during the process of building this DApp. Working on this project was really interesting and exciting for us. We faced some interesting challenges and had a lot of fun along the way.
This article was originally published on https://www.uruit.com/blog/2018/06/12/our-first-blockchain-software-project/
Click here to view the complete list of Methods & Tools articles
This article was published in July 2018
|
Methods & Tools Software Testing Magazine The Scrum Expert |
|
Discover the best available Open Source Project Management Tools (Gantt, Scrum, Kanban) Explore a list of Free and Open Source Scrum Tools for Agile Software Project Management |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


