|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Six Key Event-Driven Architecture Patterns
Natan Silnitsky, https://www.natansil.com/, @NSilnitsky
For the past year, I have been part of the data-streams team that is in charge of Wix's event-driven messaging infrastructure (on top of Kafka). This infrastructure is used by more than 1400 microservices.
During this period I have implemented or have witnessed implementations of several key patterns of event-driven messaging designs that have facilitated creating a robust distributed system that can easily handle increasing traffic and storage needs.
1. Consume and Project
...for those very popular services that become a bottleneck
This pattern can help when you have a bottleneck legacy service that stores "popular" data of large domain objects.
At Wix, this was the case with our MetaSite service that holds a lot of metadata for each site created by Wix users, like the site version, the site owner, and which apps are installed on the site — The Installed Apps Context.
This information is valuable for many other microservices (teams) at Wix, like Wix Stores, Wix Bookings, Wix Restaurants, and many more. This single service was bombarded with more than 1 million RPM of requests to fetch various parts of the site metadata.
It was obvious from looking at the service's various APIs, that it was dealing with too many different concerns of its client services.
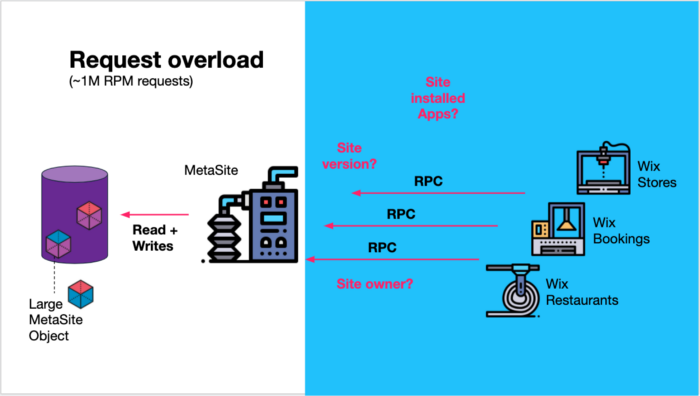
MetaSite service handled ~1M RPM various kinds of requests
The question we wanted to answer was how do we divert read requests from this service in an eventually consistent manner?
Create "materialized views" using KafkaThe team in charge of this service decided to create an additional service that would handle only one of MetaSite's concerns — "Installed Apps Context" requests from their client services.
- First, they streamed all the DB's Site Metadata objects to a Kafka topic, including new site creations and site updates. Consistency can be achieved by doing DB inserts inside a Kafka Consumer, or by using CDC products like Debezium.
- Second, they created a "write-only" service (Reverse lookup writer) with its own DB, that consumed the Site Metadata objects but took only the Installed Apps Context and wrote it to the DB. I.e. it projected a certain "view" (installed apps) of the site-metadata into the DB.
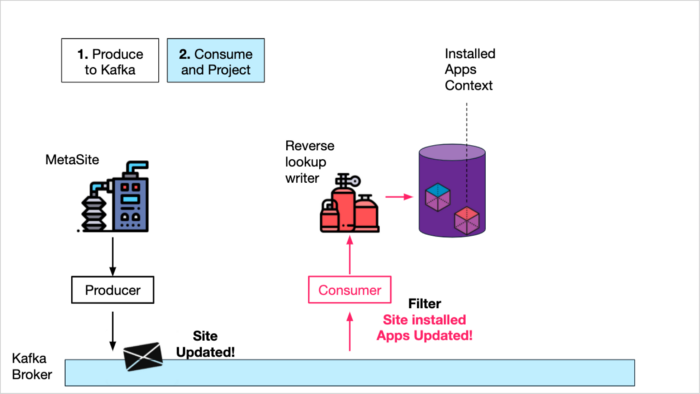
Consume and Project Installed Apps Context
- Third, they created a "read-only" service that only accepted requests related to the Installed Apps context which they could fulfill by querying the DB that stored the projected "Installed Apps" view.
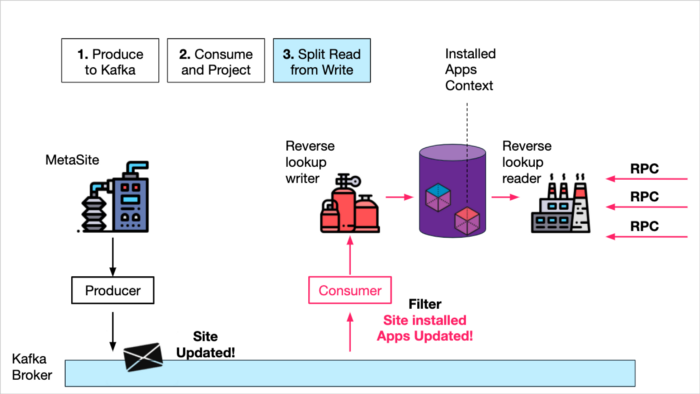
Split Read from Write
Outcomes:
- By streaming the data to Kafka, the MetaSite service became completely decoupled from the consumers of the data, which reduced the load on the service and DB dramatically.
- By consuming the data from Kafka and creating a "Materialized View" for a specific context, The Reverse lookup writer service was able to create an eventually consistent projection of the data that was highly optimized for the query needs of its client services.
- Splitting the read service from the write service, made it possible to easily scale the amount of read-only DB replications and service instances that can handle ever-growing query loads from across the globe in multiple data centers.
2. Event-driven from end to end
...for easy business flow status updates
The request-reply model is especially common in browser-server interactions. By using Kafka together with websockets we can have the entire flow event driven, including the browser-server interactions.
This makes the interactions more fault tolerant, as messages are persisted in Kafka and can be re-processed on service restarts. This architecture is also more scalable and decoupled because state management is completely removed from the services and there is no need for data aggregation and upkeep for queries.
Consider the following use case — importing all of the Wix User's contacts into the Wix platform.
This process involves a couple of services — the Contacts Jobs service processes the import request and creates import batch jobs, and the Contacts Importer does the actual formatting and storing of the contacts (sometimes with the help of 3rd party services).
Register, and we will let you knowA traditional request-reply approach will require the browser to keep polling for the import status and for the front-end service to keep the state of status updates in some DB tables, as well as to poll the downstream services for status updates.
Instead, by using Kafka and a websockets manager service, we can achieve a completely distributed event driven process where each service works completely independently.
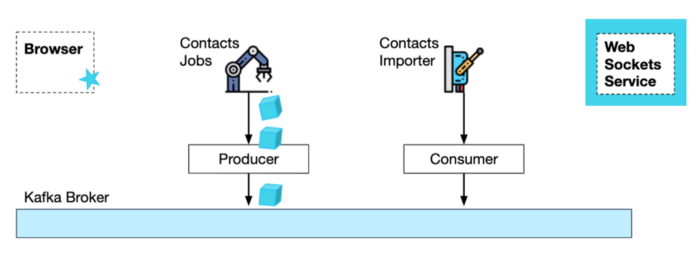
E2E event-driven Using Kafka and Websockets
First, the browser, upon request to start importing, will subscribe to the web-sockets service. It needs to provide a channel-Id, in order for the websockets service to be able to route notifications correctly back to the correct browser:
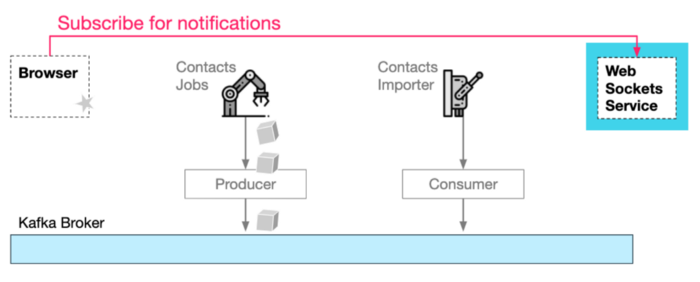
Open websocket "channel" for notifications
Second, The browser needs to send an HTTP request to the jobs service with the contacts in CSV format, and also attach the channel-Id, so the jobs service (and downstream services) will be able to send notifications to the websockets service. Note that the HTTP response is going to return immediately without any content.
Third, the jobs service, after processing the request, produces job requests to a kafka topic.
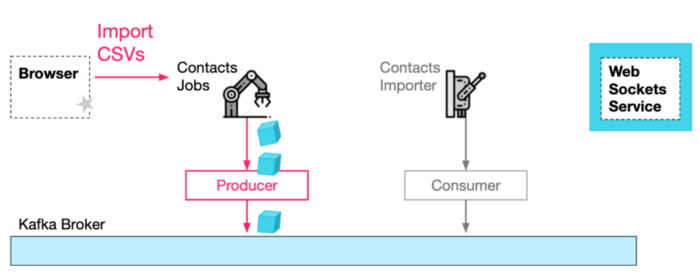
HTTP Import Request + Import Job Message Produced
Fourth, The Contacts importer service consumes the job requests from Kafka and performs the actual import tasks. While It finishes it can notify the websockets service that the job is done, which in turn can notify the browser.
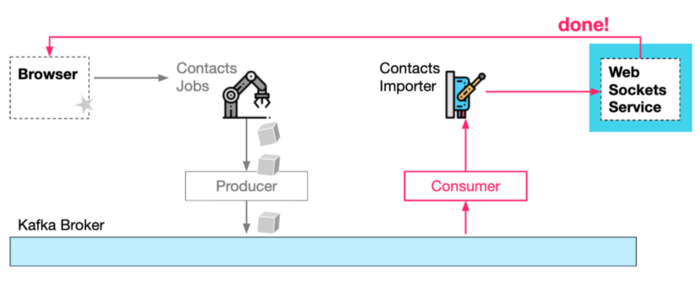
Job consumed, processed and completion status notified
Outcomes:
- Using this design, it becomes trivial to notify the browser on various stages of the importing process without the need to keep any state and without needing any polling.
- Using Kafka makes the import process more resilient and scalable, as multiple services can process jobs from the same original import http request.
- Using Kafka replication, It's easy to have each stage in the most appropriate datacenter and geographical location. Maybe the importer service needs to be on a google dc for faster importing of google contacts.
- The incoming notification requests to the web sockets can also be produced to kafka and be replicated to the data center where the websockets service actually resides.
3. In memory KV store
...for 0-latency data access
Sometimes we need to have dynamic yet persistent configuration for our applications, but we don't want to create a full blown relational DB table for it.
One option is to create one big Wide Column Store table for all your applications with HBase/Cassandra/DynamoDB, where the primary key contains a prefix that identifies the app domain (e.g. "stores_taxes_").
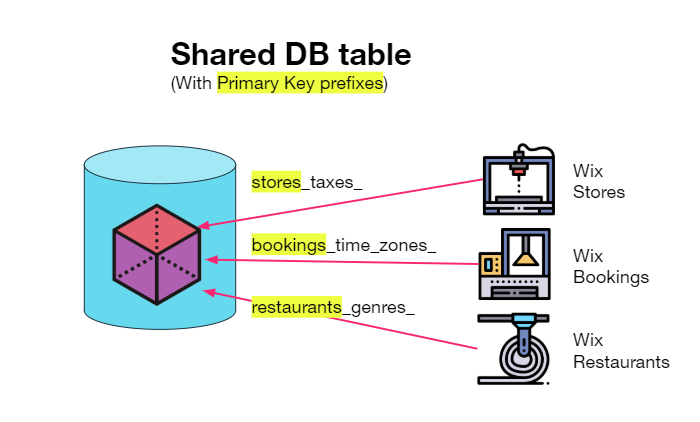
This solution works quite well, but there is built-in latency involved with fetching values over the network. It's more suitable for larger data-sets than just configuration data.
Another approach is to have an in-memory key/value cache that also has persistence — Redis AOF provides this capability.
Kafka offers a similar solution for key/value stores in the form of compacted topics (where the retention model makes sure that latest values of keys are not deleted).
At Wix we use these compacted topics for in-memory kv-stores where we load (consume) the data from the topic on application startup. A nice benefit here that Redis doesn't offer is that the topic can still be consumed by other consumers that want to get updates.
Subscribe and QueryConsider the following use case — Two microservices use a compacted topic for data they maintain: Wix Business Manager (helps Wix site owners with managing their business) uses a compacted topic for a list of supported countries, and Wix Bookings (allows to schedule appointments and classes) maintains a "time zones" compacted topic. Retrieving values from these in-memory kv stores has 0 latency.
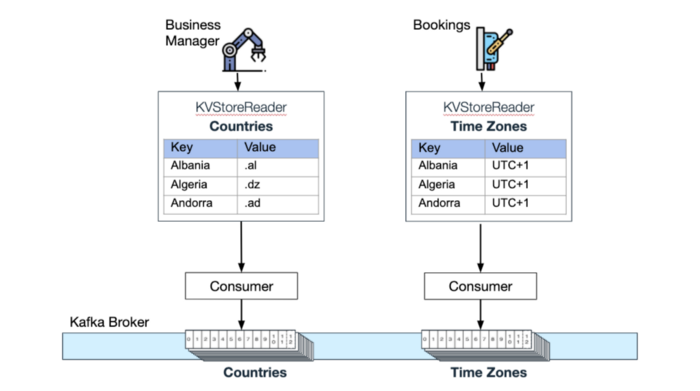
Each In-memory KV Store and their respective compacted Kafka topics
Wix Bookings listens for updates from the "supported countries" topic:
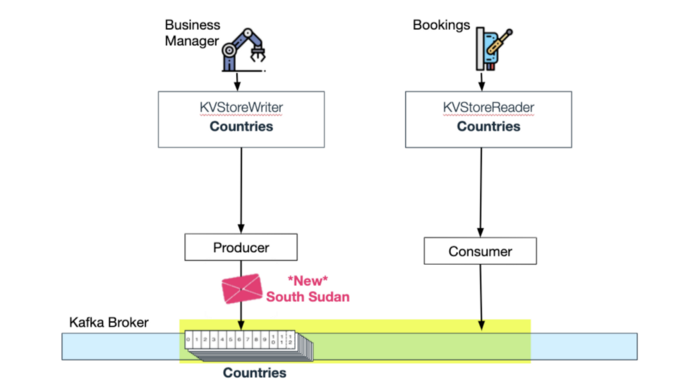
Bookings consums updates from Countries compacted topic
When Wix Business Manager adds another country to the "countries" topic, Wix Bookings consumes this update and automatically adds a new Time Zone for the "time zones" topic. Now the "time zones" in-memory kv-store is also updated with the new time zone:
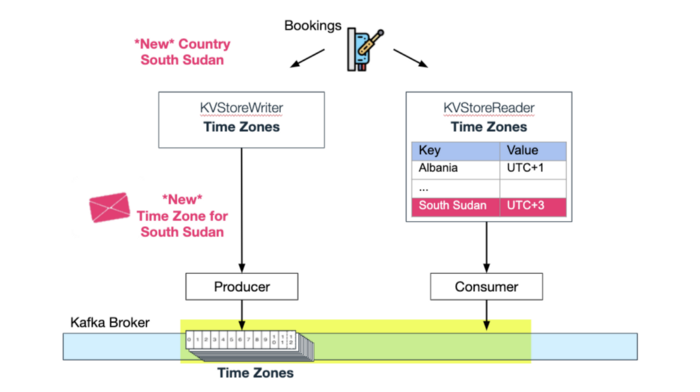
A new time zone for South Sudan is added to the compacted topic
We don't need to stop here. Wix Events (that allows Wix Users to manage event tickets and RSVPs) can also consume Bookings' time zones topic and automatically get updates to its in-memory kv-store whenever a country changes its time zone for daylight savings.
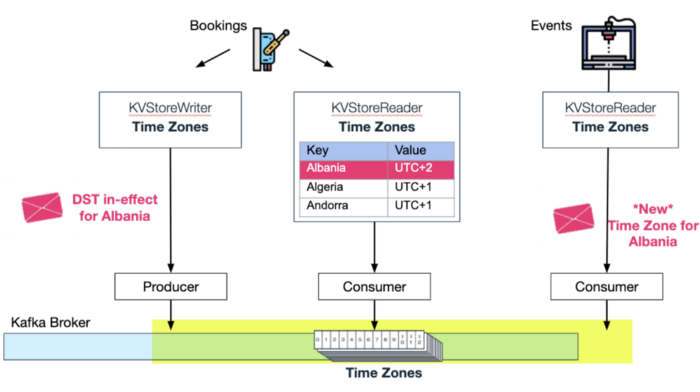
Two In-memory KV Stores consuming from the same compacted topic
4. Schedule and Forget
...when you need to make sure scheduled events are eventually processed
There are many cases where Wix microservices are required to execute jobs according to some schedule.
One example is Wix Payments Subscriptions Service that manages subscription-based payments (e.g. subscription to Yoga classes). For each user that has a monthly or yearly subscription, a renewal process with the payment provider has to take place.
To that end, a Wix custom Job Scheduler service invokes a REST endpoint pre-configured by the Payments Subscription service.
The subscription renewal process happens behind the scenes without the need for the (human) user to be involved. That is why it is important that the renewal will eventually succeed even if there are temporary errors — e.g. 3rd payment provider is unavailable.
One way to make sure this process is completely resilient is to have a frequently recurring request by the job scheduler to the Payment Subscriptions service where the current state of renewals is kept in DB and polled on each request for the expiring renewals that have yet to be extended. This will require pessimistic/optimistic locking on the DB because there could be multiple subscription extension requests for the same user at the same time (from two separate ongoing requests).
A better approach would be to first produce the request to Kafka. Why? Handling the request will be done sequentially (per specific users) by a Kafka consumer, so there is no need for a mechanism for synchronization of parallel work.
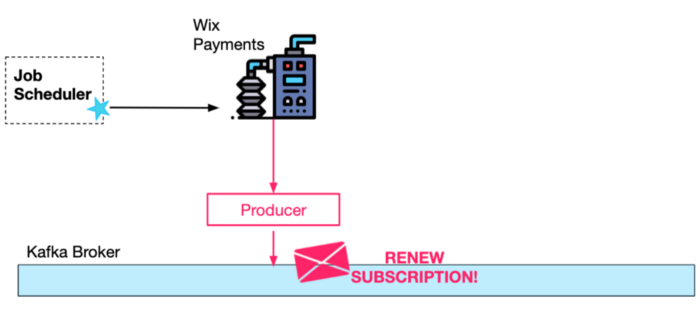
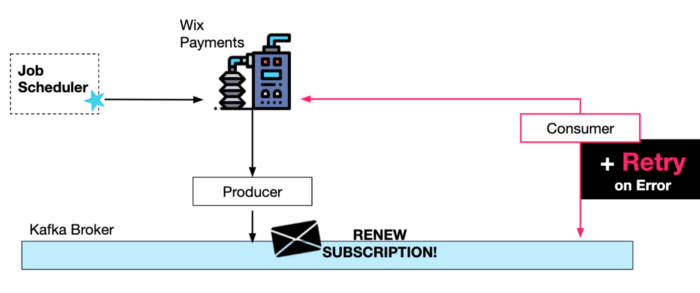
Additionally, once the message is produced to Kafka, we can make sure that it will eventually be successfully processed by introducing consumer retries. The schedule for requests can be much less frequent as well due to these retries.
In this case we want to make sure that handling order is maintained, so the retry logic can simply be sleeping between attempts with exponential backoff intervals.
Wix developers use our custom-made Greyhound consumers, so they only have to specify a BlockingPolicy with the appropriate retry intervals for their needs.
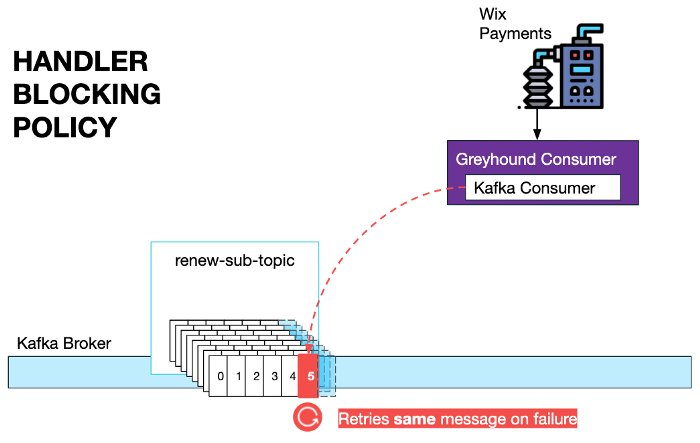
There are situations where a lag can build up between the consumer and the producer, in case of persisted error for a long time. In these cases there is a special dashboard for unblocking and skipping the message that our developers can use.
If message handling order is not mandatory, a non-blocking retry policy also exists in Greyhound that utilizes "retry topics".
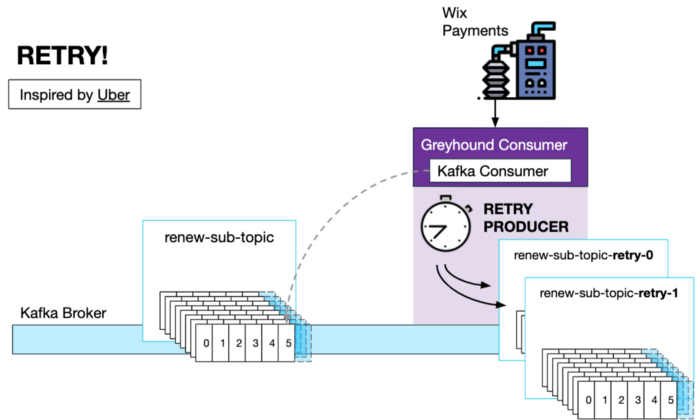
When a Retry Policy is configured, the Greyhound Consumer will create as many retry topics as retry intervals the user defined. A built-in retry producer, will upon error, produce the message to the next retry topic with a custom header specifying how much delay should take place before the next handler code invocation.
There is also a dead-letter-queue for a situation where all retry attempts were exhausted. In this case the message is put in the dead-letter-queue for manual review by a developer.
This retry mechanism was inspired by this uber article.
Wix has recently open-sourced Greyhound and it will soon be available to beta users. To find out more, you can read the github readme.
Summary:
- Kafka allows for sequential processing of requests per some key (e.g. userId to have subscription renewal) that simplifies worker logic
- Job schedule frequency for renewal requests can be much lower due to implementation of Kafka retry policies that greatly improve fault tolerance.
5. Events in Transactions
...when idempotency is hard to achieve
Consider the following classic eCommerce flow:
Our Payments service produces an Order Purchase Completed event to Kafka. Now the Checkout service is going to consume this message and produce its own Order Checkout Completed message with all the cart items.
Then all the downstream services (Delivery, Inventory and Invoices) will need to consume this message and continue processing (prepare the delivery, update the inventory and create the invoice, respectively).
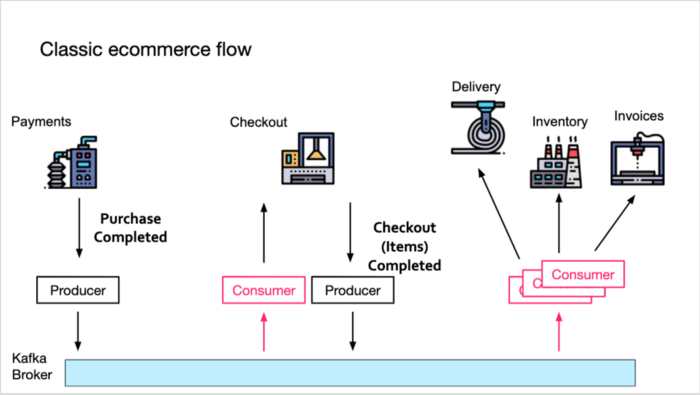
This implementation of this event-driven flow will be much easier if the downstream services can rely on the Order Checkout Completed event to only be produced once by the Checkout service.
Why? Because processing the same Checkout Completed event more than once can lead to multiple deliveries or incorrect inventory. In order to prevent this by the downstream services, they will need to store de-duplication state, e.g., poll some storage to make sure they haven't processed this Order Id before.
This is usually implemented with common DB consistency strategies like pessimistic locking and optimistic locking.
Fortunately, Kafka has a solution for such pipelined events flow, where each event is handled exactly once, even when a service has a consumer-producer pair (e.g. Checkout) that both consumes a message AND produces a new message as a result.
In a nutshell, when the Checkout service handles the incoming Payment Completed event, it needs to wrap the sending of the Checkout Completed event inside a producer transaction, it also needs to send the message offsets (to allow the Kafka broker to track duplicate messages).
Any messages produced during this transaction will only be visible to the downstream consumer (of Inventory Service) once the transaction is complete.

Also, the Payment Service Producer at the start of the Kafka-based flow has to be turned into an Idempotent producer — meaning that the broker will discard any duplicated messages it produces.
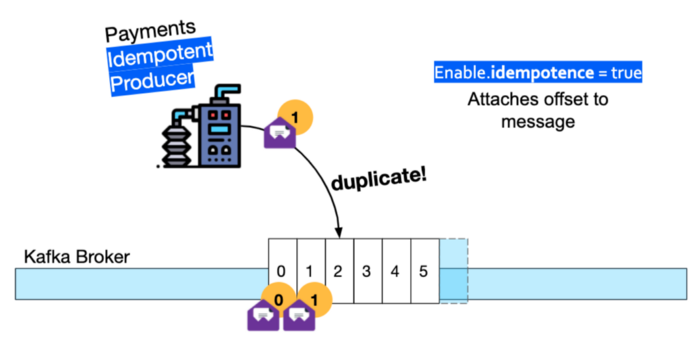
For more information you can watch my short intro talk on YouTube: Exactly once semantics in Kafka
6. Events Aggregation
... when you want to know that a complete batch of events have been consumed
Previously, I described a business flow at Wix for Importing Contacts into the Wix CRM platform. The backend includes two services. A jobs service that is provided with a CSV file and produces job events to Kafka. And a Contacts Importer Service that consumes and executes the import jobs.
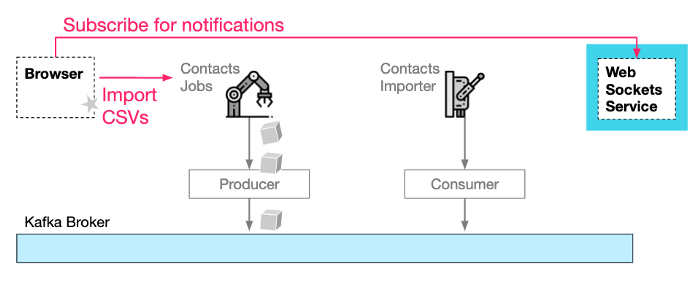
Let's assume that sometimes the CSV file is very big and that it is more efficient to split the workload into smaller jobs with fewer contacts to import in each of them. This way the work can be parallelized to multiple instances of the Contacts Importer service. But how do you know when to notify the end-user that all contacts have been imported when the import work has been split into many smaller jobs?
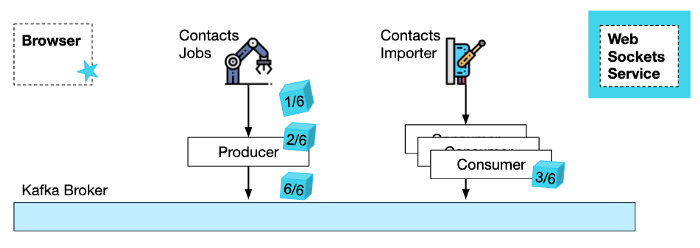
Obviously, the current state of completed jobs needs to be persisted, otherwise in-memory accounting of which jobs have been completed can be lost to a random Kubernetes pod restart.
One way to persist this accounting without leaving Kafka, is by using Kafka Compacted Topics. This kind of topic can be thought of as a streamed KV store. I have mentioned them extensively in pattern 3 of the first part of this article — In memory KV stores.
In our example the Contacts Importer service (in multiple instances) will consume the jobs with their indexes. Every time it finishes processing some job it needs to update a KV store with a Job Completed event. These updates can happen concurrently, so potential race conditions can occur and invalidate the jobs completion counters.
Atomic KV StoreIn order to avoid race conditions, the Contacts Importer service will write the completion events to a Jobs-Completed-Store of type AtomicKVStore.
The atomic store makes sure that all job completion events will be processed sequentially, in-order. It achieves this by creating both a "commands" topic and a compacted "store" topic.
Sequential ProcessingIn the diagram below you can see how each new import-job-completed "update" message is produced by the atomic store with the [Import Request Id]+[total job count] as key. By using a key, we can rely on Kafka to always put the "updates" of a specific requestId in a specific partition.
Next a consumer-producer pair that is part of the atomic store, will first listen to each new update and then perform the "command" that was requested by the atomicStore user — In this case, increment the number of completed jobs by 1 from the previous value.
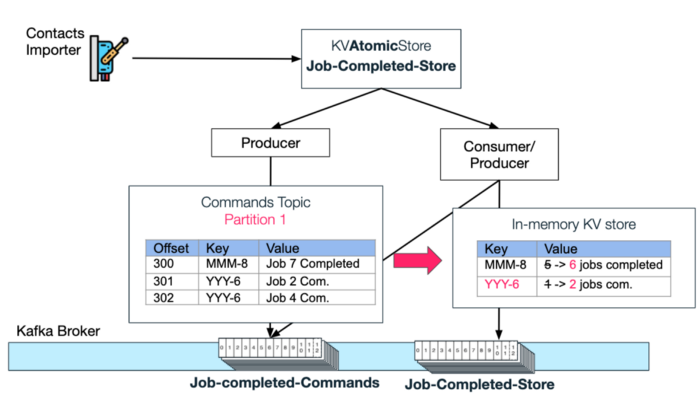
Example update flow end-to-endLet's go back to the Contacts Importer service flow. Once this service instance finishes processing some job, it will update the Job-Completed KVAtomicStore (e.g. Import Job 3 of request Id YYY has finished):
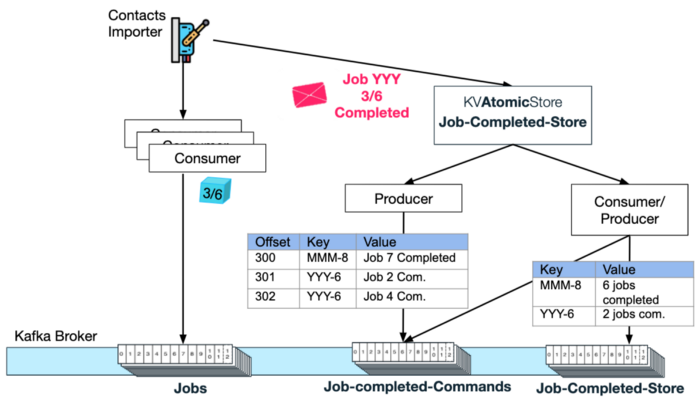
The Atomic Store will produce a new message to the job-completed-commands topic with key = YYY-6 and Value — Job 3 Completed.
Next, the Atomic Store's consumer-producer pair will consume this message and increment the completed jobs count for key = YYY-6 of the KV Store topic.
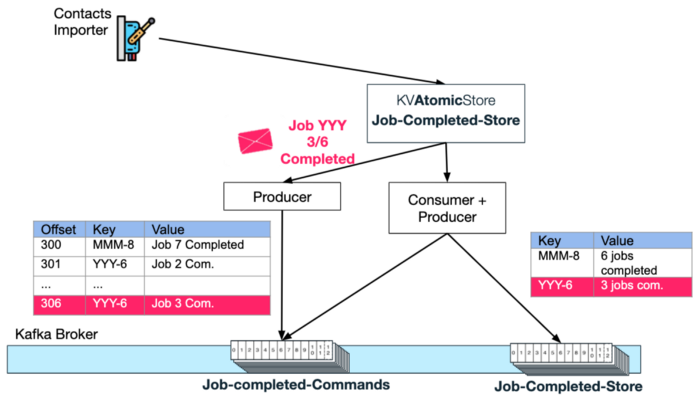
Exactly Once ProcessingNote that processing the "command" requests have to happen exactly once, otherwise the completion counters can be incorrect (false increments). Creating a Kafka transaction (as described in pattern 4 above) for the consumer-producer pair is critical for making sure the accounting remains accurate.
AtomicKVStore Value Update CallbackAnd finally, once the latest KV produced value of completed jobs count matches the total (e.g. 6 completed jobs for YYY import request), the user can be notified (via web socket) on import completion. The notification can happen as a side-effect of the KV-store topic produce action — i.e. invoking a callback provided to the KV Atomic store by its user.
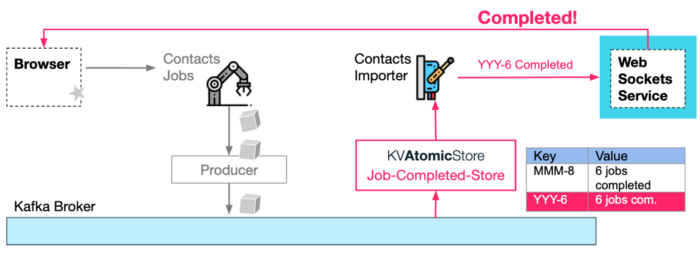
Important notes:
- The completion notification logic does not have to reside in Contacts Importer service, it can be in any micro-service, as this logic is completely decoupled from other parts of this process and only depends on Kafka topics.
- No scheduled polling needs to occur. The entire process is event-driven, i.e. handling of events in a pipeline fashion.
- There is no possibility of a race condition between jobs completion notifications or duplicate updates by using key-based ordering and exactly once Kafka transactions.
- Kafka Streams API is very natural for such aggregation requirements with API features as groupBy (group by Import Request Id), reduce or count (count completed jobs) and filter (count equal to number of total jobs) followed by the webhook notification side-effect. For Wix, using the existing producer/consumer infrastructure made more sense and was less intrusive on our microservices topology.
What I take from this
Some of the patterns here are more commonplace than others, but they all share the same principles. By using an event-driven pattern, you get less boilerplate code (and polling, and locking primitives), and more resiliency (less cascading failures, more errors and edge cases handled). In addition the microservices are much less coupled to one another (producer does not need to know who consumes its data) and scaling out is easy as adding more partitions to the topic (and more service instances).
Thank you for reading! If anything is unclear or you want to point out something, please contact me.
This article was originally published in two parts on https://medium.com/wix-engineering/6-event-driven-architecture-patterns-part-1-93758b253f47 and https://medium.com/wix-engineering/6-event-driven-architecture-patterns-part-2-455cc73b22e1. It is reproduced here with permission from Natan Silnitsky.
Related articles
Functional Architecture For IoT Platforms
How To Choose Between Microservices and Serverless Architectures
Chop Onions Instead of Layers in Software Architecture
Simple Sketches for Diagramming your Software Architecture
More Agile and Project Management Knowledge
Software Architecture, Unified Modeling Language (UML) & Data Modeling
Click here to view the complete list of Methods & Tools articles
This article was published in June 2021
|
Methods & Tools Software Testing Magazine The Scrum Expert |
|
Discover the best available Open Source Project Management Tools (Gantt, Scrum, Kanban) Explore a list of Free and Open Source Scrum Tools for Agile Software Project Management |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


