|
Software Development Magazine - Project Management, Programming, Software Testing |
|
Scrum Expert - Articles, tools, videos, news and other resources on Agile, Scrum and Kanban |
Using Entropy to Measure Software Maturity
Kamiel Wanrooij, Grip QA, https://grip.qa/
In a software development project change is one of the only constant factors. Requirements can change, as can the technical considerations and environmental circumstances. Our jobs as software project managers and engineers is largely managing this ability to change.
As software projects grow, the ability to change often diminishes. This is in contrast to the rate of change, which generally increases through the first releases until a project enters maintenance mode and is eventually End-Of-Life. This difference makes software projects unpredictable and has given rise to methodologies like Agile, Scrum and Lean to streamline the rate of change. These methodologies do not, however, help increase the ability of a software project to support this rate of change. Entropy is a metric that you can use to measure a software project's ability to keep up with the rate of change.
What is entropy?
Entropy is a term from information theory that is inspired by the concept of entropy in thermodynamics. In thermodynamics, and in general, entropy is a measure of disorder in a system. It's this disorder that also interested us in software development.
Claude Shannon first defined entropy in the context of information in 1948 in his famous paper: "A Mathematical Theory of Communication". Shannon defines entropy as the amount of information you need to encode any sort of message. In other words, how much unique information is present in the message. If you have a coin that always turns up 'heads', you don't need anything to record the outcome of a coin toss. A regular coin, you need one 'bit' of information to track if the coin came up heads or tails. A six-sided die: 2.6 bits (yes, in entropy, you can have fractions of bits).
This concept is often used in cryptography. The 'entropy' of a password is how many bits are required to store all possible combinations of a password. A 4-digit pincode carries less entropy than 16 alphanumeric characters with special characters mixed in. In cryptography, higher entropy means that it is harder to brute-force, since there are more possible combinations.
The same concept can be applied to changes made in a software project. If a change only affects a small part of the system, that change can be recorded with very few bits of information. If changes touch a large part of a system, you need many more bits to encode that change.
Using this logic, we can determine the impact of changes by calculating the entropy that each change carried. In a typical software project, the larger part of the system you need to modify to implement a feature or change, the harder it is to implement that change. Thus looking at the entropy of past changes tells us something about our ability to make those changes efficiently.
Coupling in software
One of the most common goals in software architecture is managing coupling. Coupling is the dependency of one part of the code to another. They are 'coupled' together, either explicitly or implicitly.
Explicit coupling happens when one part of the code directly depends on or uses the other. This is unavoidable, but should be carefully managed. A tightly coupled system can become brittle and hard to change. Most design patterns that deal with explicit coupling implement some form or part of the SOLID or DRY principles.
SOLID is an abbreviation of 5 best practices in Object Oriented software development: Single responsibility, Open-closed, Liskov substitution, Interface segregation and Dependency inversion. The impact of these best practices is beyond the scope of this article, but they're all designed to help create maintainable software architectures.
DRY stands for Don't Repeat Yourself, and is an often-heard mantra for developers. Not only does repeating yourself create additional work now, it also increases the maintenance burden later on. All repeated sections will probably require the same bug fixes and changes applied to them, if the developer remembers that the duplicate sections exist!
Implicit coupling can occur when there is no direct relationship in the code between two parts, but they are conceptually or otherwise linked together. This is usually harder to detect since it requires knowledge of how different components interact to see if changes in one also affect another.
Measure entropy in software
Measuring entropy can quickly turn into a very technical discussion. For the examples in this article we're using a very simple implementation of entropy that still caries a lot of value.
I'll define entropy as the amount of data required to count the number of files changed with each commit in the source control system. This definition is based of the assumption that each file is a logical, consistent unit that belongs together. Multiple changes to one file add just one bit of entropy to our commit. But as soon as changes cover multiple files, the entropy goes up in a logarithmic scale:
- 1 file: 0 bits of entropy
- 2 files: 1 bit of entropy
- 4 files: 2 bits of entropy
- 16 files: 4 bits of entropy
- 1024 files: 10 bits of entropy
As you can see, with each bit of entropy the scope of each change doubles. This makes our definition easy to work with. It's not going to be perfect since there's obviously a lot more information in each commit than simply the number of files changed. The advantage is that it provides some valuable insights without getting too technical or too hard to compute.
Examples of entropy
The following images contain some examples of entropy during the development process. The black line represents the daily average entropy. The red line is a 30 day rolling entropy average. The blue vertical lines represent minor releases (dotted) and major releases (solid).
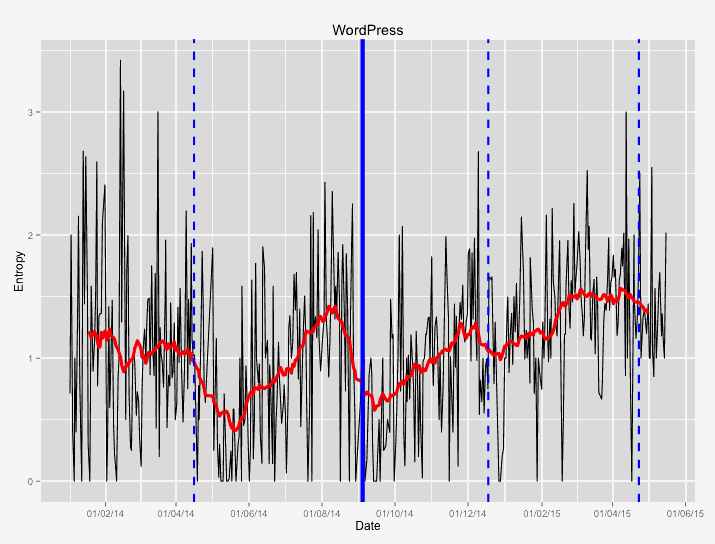
This is an entropy analysis of the WordPress repository over the past 18 months. There are a number of peaks and valleys that coincide with the past releases. Most releases happen after a peak in entropy has passed and entropy levels have started to go back to normal levels. The average entropy slowly slides upward.
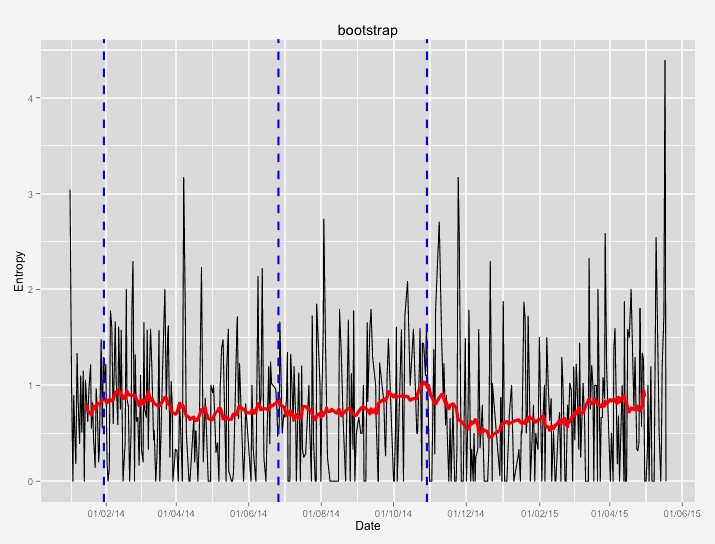
We see a totally different picture looking at the Bootstrap repository. The overall entropy is quite low with an average of less than 1 bit and has very small peaks. This indicates that over the past 18 months, changes could be made very consistently. The only peak above 1 bit was quickly followed by a maintenance release that reduced entropy again.
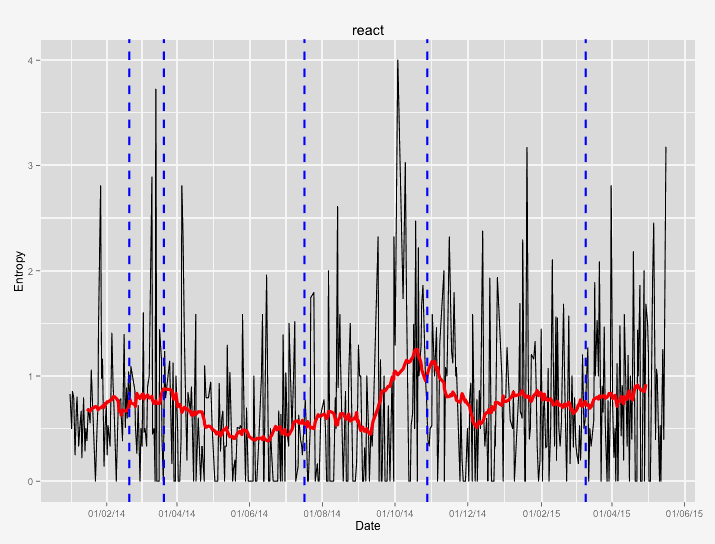
React shows just one significant peak in the same period, with some minor fluctuations. The overall entropy is well below 1 bit, indicative of a mature codebase with the right degree of decoupling.
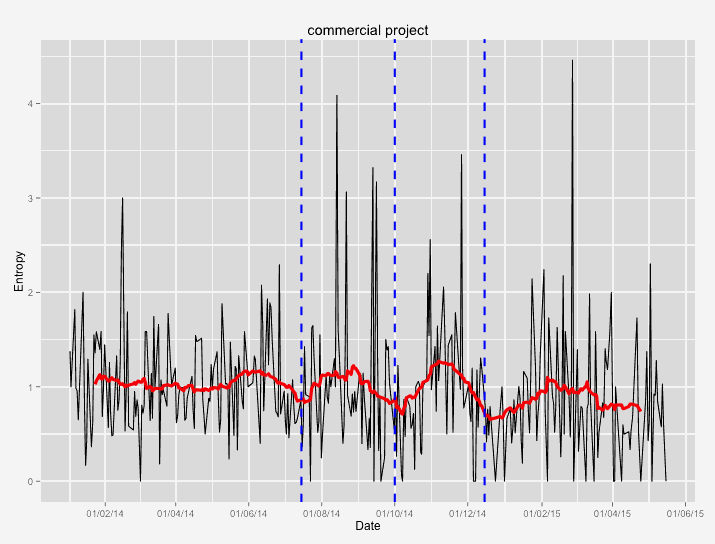
This is a commercial project that I worked on. Entropy was stable but begins to fluctuate slightly as the technical limits of the system draw closer. Their current goal is to stabilize at a lower level than at the start of the measurements to facilitate future change.
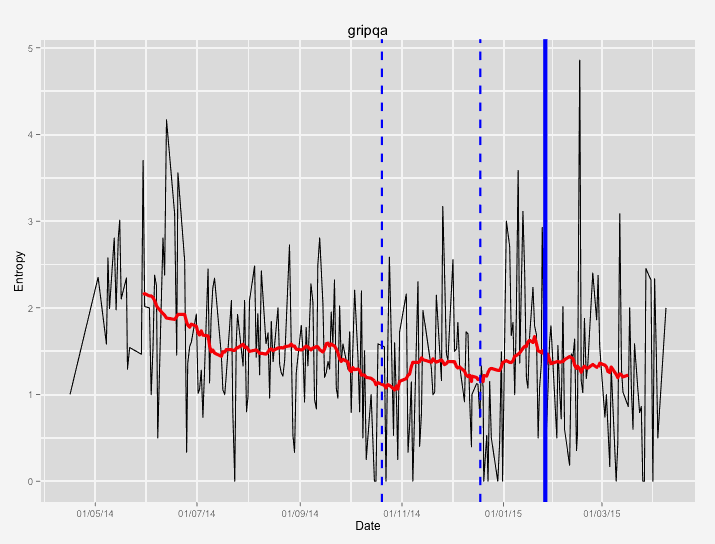
This is our internal product development. We had been doing greenfield development for almost a year, only bringing down entropy right before the internal test releases and our public beta release. The current entropy is still above 1 bit, in contrast to some of the more mature projects that are well below 1 bit of entropy on average.
Causes of entropy
As seen above there is a lot of overlap between the effects of coupling and the way we measure entropy. Both deal with effects spanning across multiple areas of the codebase, and indeed coupling is a major contributor of entropy.
Some of the most obvious ways coupling can introduce entropy occur when there is a high degree of structural coupling. Changing a class name or adding parameters to a method often requires all places where this is referenced to be updated as well. The heavier one file relies on these details in other files or modules, the higher the effect is on entropy.
More generally, most violations of the DRY principle can introduce higher levels of entropy. As soon as any representation, functional or technical, is duplicated across the system, it requires more effort to change that.
More subtle ways that can still have an impact in entropy are functional or implicit in nature. When two objects share some mutable state for instance, they are effectively tied together by that state. Modifying one can introduce changes in behavior in the other, requiring a second change to offset that unwanted behavior.
Apart from coupling a more desirable method that introduces a lot of entropy is a large system refactor. When removing coupling between modules initially you'll also touch upon all affected modules. Highly coherent modules, which are modules that are very tightly related by design, can also introduce more entropy.
Other ways that increase entropy, either desirable or unwanted, are writing automated tests along with the implementation; unfocussed, broad functional changes tied together in a single change; initial setup of systems or libraries.
Effects of entropy
Entropy itself is not necessarily a bad thing, but it is an indication of stability and maturity of the development process. Since coupling is a major contributor to entropy, tracking entropy is a good way to see which areas of your system are explicitly or implicitly tightly coupled. This might not be easy to do just by a static analysis of the codebase itself.
Periods of high entropy changes indicate areas that are likely to be dependent on each other. Changes to one part might introduce bugs or rework on the related parts. As the scope of changes increases, the risks and testing efforts also increase.
Even after entropy levels decrease, those high-entropy changes introduced are still present in the systems. This could affect future changes in a negative way, so a lower entropy level does not necessarily mean that it won't increase again in the future. Whenever the rate of change is low this is not so bad, but as the rate of change increases those areas will again introduce higher entropy levels.
Since entropy is both a measure of the rate of change and the breadth of those changes, it's very relevant when scheduling releases. During periods of high entropy it is highly inadvisable to release since changes still have high impact and risk. When entropy decreases, this indicates that changes are more local and thus easier to implement and test. These are the changes that can be done safely closer to a release.
Preventing high entropy
There are many ways that entropy can be prevented using software design principles such as DRY and SOLID and creating abstractions with the correct level of detail. It also helps to define your systems with proper consistency boundaries that match your problem domain.
It's always a good practice to be aware of these principles and to incorporate them into your coding habits. Team members should encourage each other to frequently revisit these principles and exchange ideas on how to improve their craft.
Not all of these things can be designed up front. While it certainly helps to understand the domain before designing technical systems, it's not always clear up front how to structure the technical systems. Overdesigning software can certainly lead to entropy later on in the development process.
As a system matures it's impossible to prevent areas that are tightly coupled together. Keeping track of this by measuring entropy helps to identify these areas before the impact of them grows so large that it introduces major risks to the development process.
Conclusion
While high entropy is not a problem in itself, it is a common result of software projects that struggle with efficiently responding to changes. A lack of some development best practices such as SOLID and DRY design frequently causes increased levels of entropy. A non-technical contributor to entropy can be an unfocussed functional specification process.
None of these are guaranteed to introduce entropy, and not all entropy is an indication of these problems. Some entropy can even be caused by very legitimate and valuable changes, but because entropy is closely related to a number of best practices, it is a valuable metric to track as part of release management.
More Methods & Tools articles on metrics and measurement
Everything You Always Wanted to Know About Software Measurement
How to Quantify Quality: Finding Scales of Measure
Click here to view the complete list of archived articles
This article was originally published in the Summer 2015 issue of Methods & Tools
|
Methods & Tools Software Testing Magazine The Scrum Expert |
|
Discover the best available Open Source Project Management Tools (Gantt, Scrum, Kanban) Explore a list of Free and Open Source Scrum Tools for Agile Software Project Management |
Copyright © by 1995-2025 Martinig & Associates |
Privacy
Follow Methods & Tools on


